Let me start this post by saying I’m a huge Google fan. I use multiple Android devices and like many others, I’ve become an avid user of services such as Gmail, Docs, Maps, Photos, and Youtube. I even find myself fondly reminiscing about discontinued services such as Reader. And, if you’re like me, Google search has become an instrumental tool in your professional endeavors. So please keep in mind, this post is not intended to bash Google or denounce its services.
That being said, sometimes it seems as if Google goes out of its way to make my job as a security professional difficult. Why you ask? Well, you’ve probably seen the posts and articles over the last few years, like these from Sophos, outlining how Google docs is a favorite method for phishers to stand up temporary web forms for use in credential-stealing campaigns.
- Google Docs – a full-featured, full-service phishing facility?
- Phishing with help from Google Docs
- Oxford University blocks Google Docs because of phishing attacks.. for 2.5 hours
As a Infosec professional for a medium-to-large organization, I’ve seen my share of these attacks.

Most are blocked or at least detected in relatively short order, but they’re still effective. Why? I can think of several reasons. For starters, it takes very little effort to create one of these forms. While Google does provide a means to report these phishing sites, by the time they are removed, the damage is usually done and the phishers are moving on to create their next form.
Second, blocking individual Google sites is typically not an option for organizations because, quite frankly, reliably blocking any portion of Google is difficult. Between its wildcard certs and the ever-changing pool of IP addresses, trying to manage DNS entries becomes unwieldy and relying on 3rd-party services to block sites based on categorization is unreliable. Without the use of SSL interception (which presents it’s own set of problems), blocking Google is usually either an all-or-nothing decision — and “nothing” almost always wins out out for the needs of the business. This means that even when your organization identifies a malicious Google form, blocking it is next to impossible and all that can be done is to report it and wait for Google to remove it.
Third, our users have an inherent trust in Google. What do we typically teach them when it comes to spotting and avoiding malicious links?
- Is the link from a trusted source? – To most users the answer it an unequivocal yes, since most are like me and probably use at least one of Google’s services daily.
- Is the data transferred over an encrypted channel and does the site use a valid certificate? – Again, the answer is yes.
Of course we also teach users never to click on links in emails received from an untrusted sender but account spoofing definitely ups the success rate (try to get your users to consistently inspect an email header). We also teach them to never enter passwords on an unfamiliar, external domain, but again, this becomes a mixed message to some…after all, these users trust Google with their personal passwords every day; why shouldn’t they trust it now?
So, we implement two-factor or adaptive authentication solutions to make basic credential stealing ineffective. But we still have to worry about phishing attacks that are designed to propagate malware — something that many organizations are also all-to-familiar with. Unfortunately, Google plays a role in aiding these attacks as well.
I recently noticed some Google services allow unvalidated redirects. Now before I get into the details, here is Google’s official position on this subject (http://www.google.com/about/appsecurity/reward-program/#notavuln):
- URL redirection. We recognize that the address bar is the only reliable security indicator in modern browsers; consequently, we hold that the usability and security benefits of a small number of well-designed and closely monitored redirectors outweigh their true risks.
Fair enough. For me, the takeaway terms are “well-designed” and “closely monitored”. Now let’s take a look at a couple of examples.
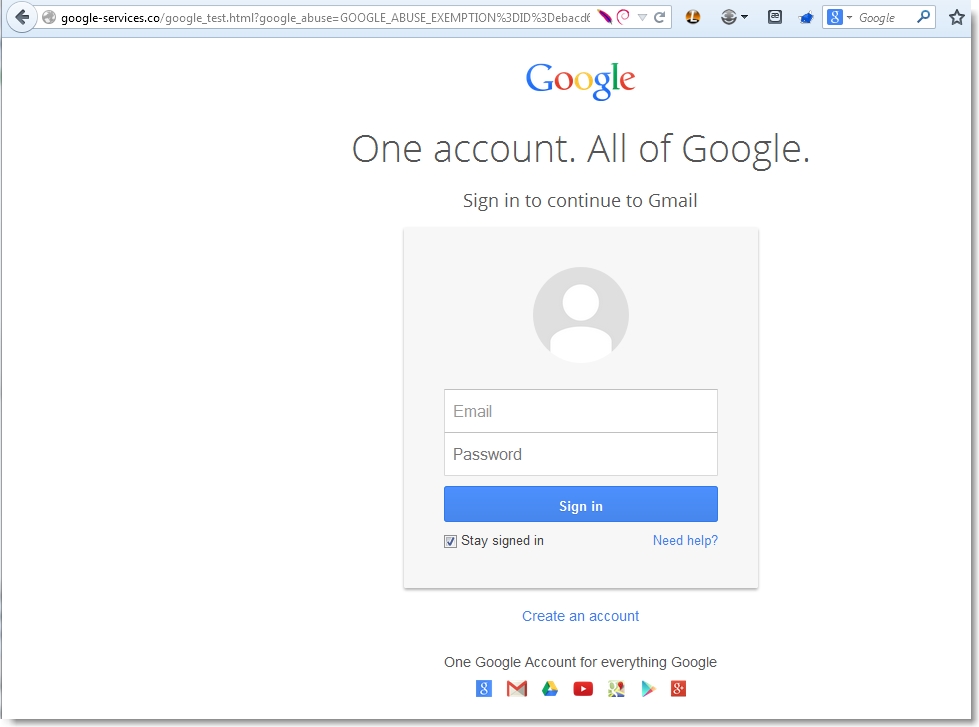
If you pay attention to the links associated with various requests for Google services, you’ll may notice the frequent use of the continue parameter. This parameter dictates where the user will be directed following the completion of the current request. For example, if you were to access mail.google.com, you should be presented with the following login page.
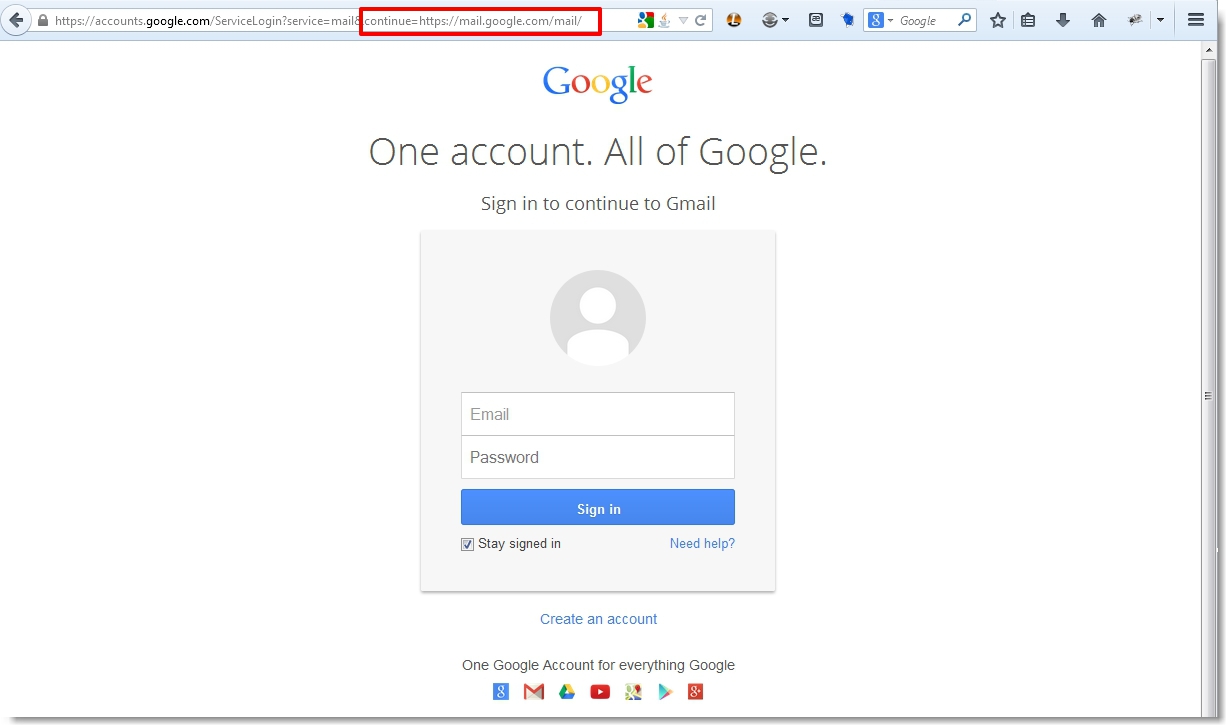
Following successful authentication, you are redirected to the location dictated by the continue parameter. In this case, any attempts to modify this to a different URL value should fail.
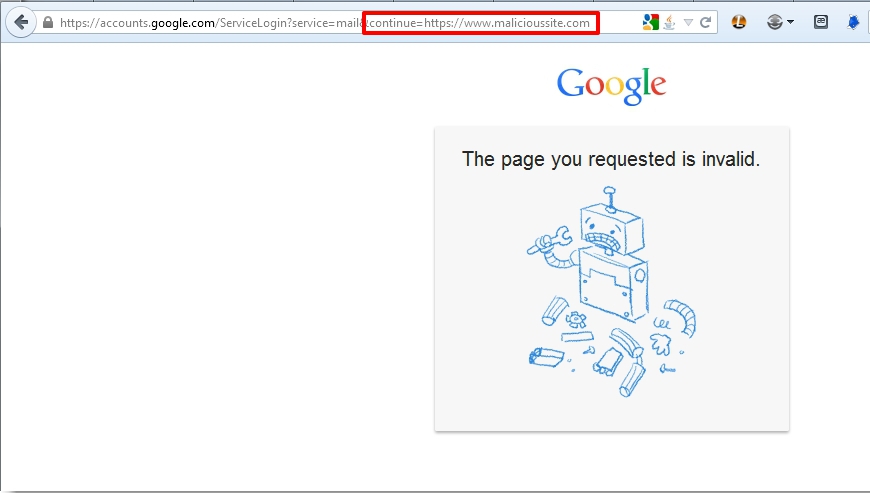
Other Google-owned services behave similarly, at least by providing some explicit warning.

However, this redirect validation is not applied consistently. Take for example this link which, at the time of my testing, immediately redirected me to Facebook without warning:
https://appengine.google.com/_ah/logout?continue=http://www.facebook.com
It should be apparent how this can be used in a phishing attack, but here’s a short illustration.
A user receives a phishing email such as the following (pardon my lack of creativity):
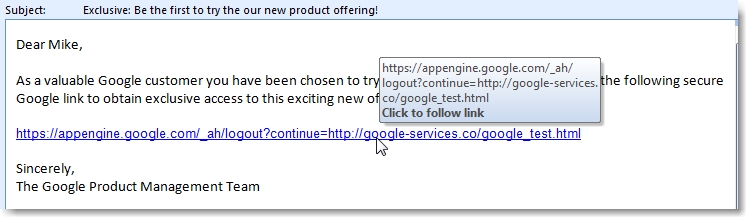
Because of their inherent trust in Google, they click the link, not noticing that the continue parameter takes them to a not-so-cleverly disguised non-Google site configured to mimic the Google account login page:
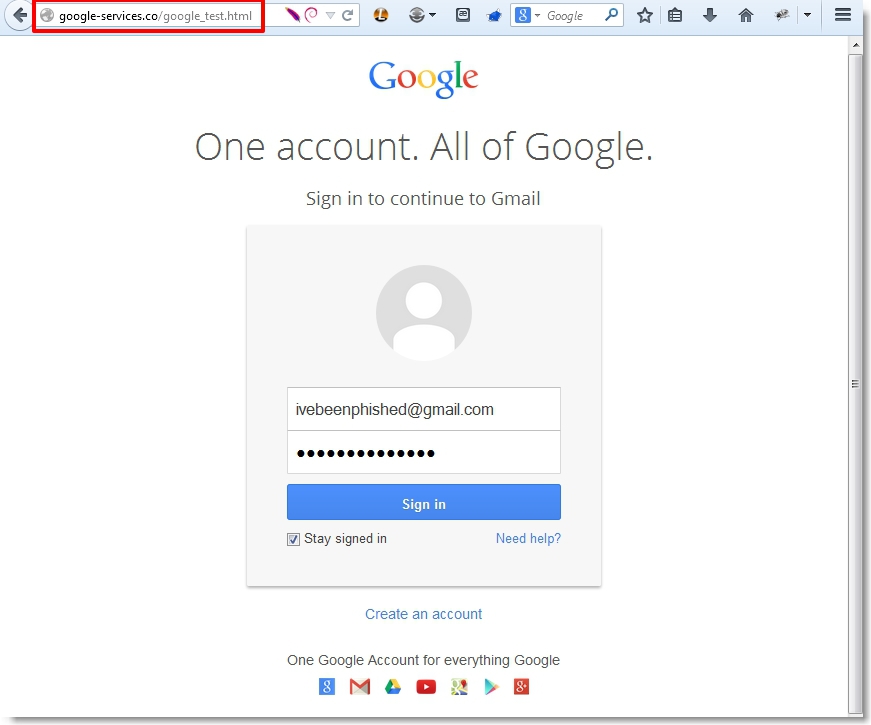
Unfortunately, this page is really designed to steal their credentials:

Upon hitting the “Sign In” button, they are immediately redirect to Gmail. If they happen to utilize the “Stay signed in” function and they already have an authenticated session, they’ll be redirected to their email account, none-the-wiser:
Otherwise, they’ll be directed to the Google sign-in page:
Of course, either way it doesn’t matter because by this point, their credentials have been compromised.
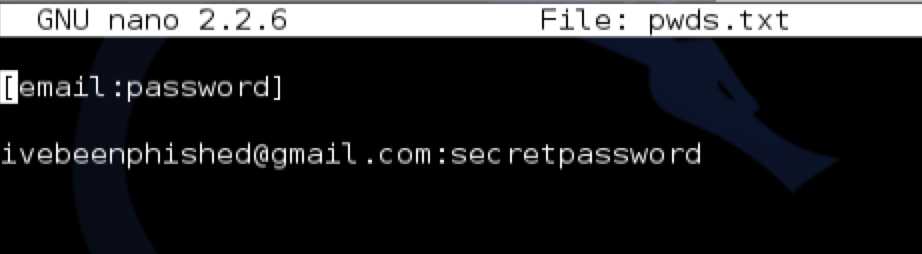
This is not the only Google service that allows unvalidated redirects. The CAPTCHA functionality also has this vulnerability:
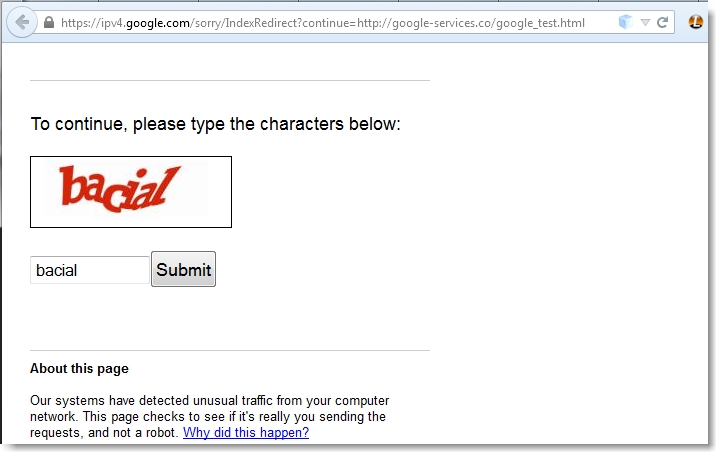
So, if you wanted to add an additional perception of “security” to your phishing attack, you could incorporate the real Google CAPTHA function. Note: If you look at the URL in the above screenshot, you’ll notice the GOOGLE_ABUSE_EXEMPTION cookie parameter which is automatically appended to the resulting GET request. I have not been able to find much information about this cookie but it clearly does not seem to perform any meaningful security function.
UPDATE #1:
I’ve created a demo video illustrating that these unvalidated redirects were successfully executed using a demo phishing page hosted on a public-facing server (pages have since been taken down) and the user is given no warnings or messages about redirecting to a non-Google domain.
The above example only illustrates a phishing attack with the purpose of stealing credentials, though this could just as easily be used to redirect a user to a malicious page hosting drive-by downloads, malicious javascript, or other malware targeting browser vulnerabilities. The key takeaway is that a phisher’s initial goal is to get a user to open an attachment or click a link and providing users a link to a “secure” site they trust only increases the likelihood of success.
I reached out to Google on this issue, being sure to explain that I had indeed read their stance on redirects, but that I could not see how these redirectors were either “well-designed” or “closely monitored”.
Unfortunately, I received a seemingly-generic email response pointing me back to the very same FAQ:
In this particular case, we believe the usability and security benefits of a well-implemented and carefully monitored URL redirector tend to outweigh the perceived risks.
For a more detailed explanation, check the URL redirection section here: http://www.google.com/about/appsecurity/reward-program/#notavuln
This is certainly not the most sexy or technically advanced vulnerability but I don’t see a reason why all redirections to Google services can’t be handled consistently — with some validation to prevent redirection to an untrusted site. In general, redirections to external sites are difficult to manage securely unless they are whitelisted. Of course, if re-directions are only required to other intra-domain services, then any external link should be rejected. Being on the outside looking in, I won’t pretend to understand all of the requirements or nuances of each redirector utilized by Google nor will I discount any protections that are in place but might not be readily apparent via my basic testing. That said, many of the Google services I tested did prevent unvalidated redirects, so my simple question is why can’t all? It’s hard enough managing a successful anti-phishing campaign in any large organization without “trusted” services such as Google providing additional weapons for our adversary’s arsenals. So please Google, help us out!
– Mike
=========================================================================
UPDATE #2
I received a couple of follow-up emails from the Google Security Team (who has been very responsive). In the interest of full disclosure here are portions of those communications. The first response from Google was as follows:
This redirector is monitored for abuse, and is a particular poor target for phishing, since it’s a page warning the user of suspicious activity related to a specific URL. A user who chooses to go to that URL anyway is intentionally putting themselves at risk. Additionally, when our monitoring detects that users are being redirected to a URL, it will be scanned for phishing/malware (if it hadn’t been already via our web crawler), and if found, that site will display a warning in browsers that support the stopbadware.org blacklist (which is most of the major ones, to my knowledge).I hope that is a sufficient explanation of how this works, and why we don’t consider this a security risk.
[…] I’m not sure what you mean by a “page warning”. My testing did not illicit any warnings about a redirection. I’ve also tested another redirector (https://appengine.google.com/_ah/logout?continue=) that exhibited the same behavior, only this one does not require any user interaction. In both tests I used a “malicious” phishing login page that was generated by copying the source of your login page. I merely altered the form to redirect to another php page hosted on my web server to capture the creds and redirected the user back to Google. All test pages were hosted on a public-facing web server accessible to Google servers. There was no apparent phishing/malware scanning…at least none that prevented the redirect to my fake login page, nor were there any warnings presented to the end user. […]
Thanks for the feedback. We’re aware of the issue with the OR in appengine, and are monitoring that situation and discussing potential improvements with the team.Testing your own phishing page isn’t going to generate enough activity to trip our detection, since what we’re looking for are active, real, phishing campaign (which, as a responsible researcher, aren’t a part of your tool kit).