Introduction
Recently, while watching the House Committee hearings on the security of Healthcare.gov, I was disappointed to hear testimony likening passive reconnaissance to a form of unauthorized/illegal activity that involved potentially invasive actions such as port/vulnerability scanning. To the contrary, passive recon can be one of the most useful and unobtrusive methods of data gathering for any penetration test or security assessment. In this post I outline what passive reconnaissance entails and the various techniques one can use.
What is passive reconnaissance?
Sometimes referred to as Open Source Intelligence (OSINT) or simply Information Gathering, the idea behind passive reconnaissance is to gather information about a target using only publicly available resources. Some references will assert that passive reconnaissance can involve browsing a target’s website to view and download publicly available content whereas others will state that passive reconnaissance does not involve sending any packets whatsoever to the target site. For the purposes of this tutorial, I’m going to refer to the Penetration Testing Execution Standard’s definitions of “passive reconnaissance” and “semi-passive reconnaissance” and group them both under the umbrella of “Passive Reconnaissance” activities.
Passive Information Gathering: Passive Information Gathering is generally only useful if there is a very clear requirement that the information gathering activities never be detected by the target. This type of profiling is technically difficult to perform as we are never sending any traffic to the target organization neither from one of our hosts or “anonymous” hosts or services across the Internet. This means we can only use and gather archived or stored information. As such this information can be out of date or incorrect as we are limited to results gathered from a third party.
Semi-passive Information Gathering: The goal for semi-passive information gathering is to profile the target with methods that would appear like normal Internet traffic and behavior. We query only the published name servers for information, we aren’t performing in-depth reverse lookups or brute force DNS requests, we aren’t searching for “unpublished” servers or directories. We aren’t running network level portscans or crawlers and we are only looking at metadata in published documents and files; not actively seeking hidden content. The key here is not to draw attention to our activities. Post mortem the target may be able to go back and discover the reconnaissance activities but they shouldn’t be able to attribute the activity back to anyone.
Keep in mind that for the purposes of my demonstration, even those activities that might be considered semi-passive do not stray outside the bounds of navigating a site in the manner that was intended. Browsing web pages, reviewing available content, downloading posted documents or reviewing any other information that has been posted to the public domain would all be considered in-scope. It does not involve actions such as sending crafted payloads to test input validation filters, port scanning, vulnerability scanning, or other similar activities which would fall under the definition of active reconnaissance. If you believe your information gathering activities might be considered active reconnaissance you must ensure they are within the scope of your assessment rules of engagement.
Should you have access to the internal network, other tools and techniques including direct observation, and passive OS fingerprinting (using tools such as P0f) and even dumpster diving are sometimes also considered passive reconnaissance. For the purposes of this tutorial, I will only demo activities that can be undertaken external to the target organization.
Scope and ROE
When you perform passive recon activities for a pentest or assessment you’ll undoubtedly have an agreed upon target and scope. For this tutorial, I won’t pick a single target but given the recent discussions of passive reconnaissance in the context of healthcare.gov I figured I’d use the *.gov domain to scope my efforts. Although all of the data is being gathered solely from the public domain without malicious intent, I’ve taken a couple of additional steps to avoid exposing details of any discovered egregious vulnerabilities.
- First, as already stated, although a penetration test or security assessment would typically be scoped to a single or select few targets, I’m not using a single .gov site to demonstrate these techniques as I did not feel it was necessary to gather and expose too much information for one organization.
- Second, I’m redacting identifying information that might disclose the exact location of a potentially damaging vulnerability or reveal a particular individual whose full name or contact information is inconsequential to understanding the demonstrated passive recon technique. Of course, the redaction doesn’t completely de-identify the context of the discovery and it’s still possible to determine what sites/organizations they belong to … after all, I did find it in the public domain.
- Third, when appropriate/possible I’m reporting discovered vulnerabilities to the respective organization for remediation. Again, any discovered vulnerabilities are already in the pubic domain for anyone to see, but I still felt an obligation as a security professional to have them remediated when possible.
Once again, none of these techniques involve maliciously scanning or probing a given website. All of this information has been gathered from the public domain using techniques and tools readily available to anyone. Also note that I use terms such as “attack” (e.g. “social engineering attack”) throughout the post, but I am not at all suggesting malicious activity. Any active reconnaissance or testing activities should only be conducted within the scope of sanctioned penetration tests or security assessments.
References
This tutorial certainly will not be all-inclusive. There are many tools and resources available when performing passive reconnaissance activities and I won’t attempt to demonstrate them all. Throughout this post I’ll reference the various websites and tools that I regularly use, though there are plenty of others. In addition, here are some other resources you might find useful:
- Penetration Testing Framework: Refer to the “Network Footprinting” section for valuable steps and tools to use when performing passive reconnaisance activities
- The Penetration Testing Execution Standard: A good reference outlining the steps involved in passive reconnaissance
- ShackF00: While I was writing this post, Dave Shackleford (Voodoo Security) posted a useful link of available search engines for OSINT/recon activities, a couple of which I reference below.
- Google Hacking For Penetration Testers: This book by Johnny Long is the original reference on Google hacking techniques. Having been released in 2008, it’s definitely dated and many of the techniques are not longer applicable to today’s Google search syntax, but if you’re a complete novice, I think it’s an important reference for understanding the concepts behind finding information in the public domain.
- Google Hacking Database: Started by Johnny Long and now maintained by Offensive Security on the exploit-db site, this is the definitive resource for Google hacks.
- Web Application Hacker’s Handbook: A must-have for anyone looking to learn about Web Application Security.
- Silence on the Wire: A Field Guide to Passive Reconnaissance and Indirect Attacks by Michal Zalewski: A great read if you want to go beyond the web-based passive recon techniques discussed here. It explores reconnaissance though IP packet inspection, traffic analysis, TEMPEST, and more.
Passive Recon Activities
I’ve organized this tutorial in a way that I hope demonstrates the types of information that can be gathered through passive reconnaissance. Here are the primary tasks that I will demonstrate:
- Identifying IP Addresses and Sub-domains — usually one of the first steps in passive reconnaissance, it’s important to identify the net ranges and sub-domains associated with your target(s) as this will help scope the remainder of your activities.
- Identifying External/3rd Party sites — although they may not be in scope for any active penetration testing activities, it is important to understand the relationships between your target and other 3rd party content providers.
- Identifying People — Identifying names, email addresses, phone numbers, and other personal information can be valuable for pretexting, phishing or other social engineering activities.
- Identifying Technologies — Identifying the types and versions of the systems and software applications in use by an organization is an important precursor to identifying potential vulnerabilities.
- Identifying Content of Interest — Identifying web and email portals, log files, backup or archived files, or sensitive information contained within HTML comments or client-side scripts is important for vulnerability discovery and future penetration testing activities.
- Identifying Vulnerabilities — it’s possible to identify critical vulnerabilities that can be exploited with further active penetration testing activities soley by examining publicly available information
It’s important to note that while I break these up into distinct topics for demonstration purposes, these activities are not necessarily compartmentalized or mutually exclusive. As you browse a target site, you may identify a person of interest, notice a key technology, uncover an interesting web portal login and realize a potential vulnerability all at the same time.
Identifying IP Addresses and Sub-Domains
While most of the passive reconnaissance activities do not have to follow a strict order, before you dive into vulnerability discovery, you should gather some basic data about your target(s) to properly scope the rest of your recon activities. After all, it doesn’t make much sense to spend a lot of time looking for PHP or MySQL vulnerabilities when you’re dealing with a .NET/SQL Server environment.
You’ll want to identify the various sub-domains and associated net range(s) related to your target. Keep in mind, just because you’re interested in www.target.gov, doesn’t mean you should restrict your passive recon activities to that address. If you do, you’re likely to miss some valuable information and/or vulnerabilities. WHOIS, Google, Maltego, Intercepting Proxies, Web Spiders, Netcraft, and sites such as Pastebin.com can all be useful resources.
Whois
Assuming you already have a defined target and scope, one of the first things you’ll want to do is a simple Whois lookup to determine where the site is hosted, who owns the IP block, if there are any organizational contacts listed that might be useful for a social engineering exercise (assuming that’s in the scope of your sanctioned test), etc.
For example, here’s the Whois information for healthcare.gov:
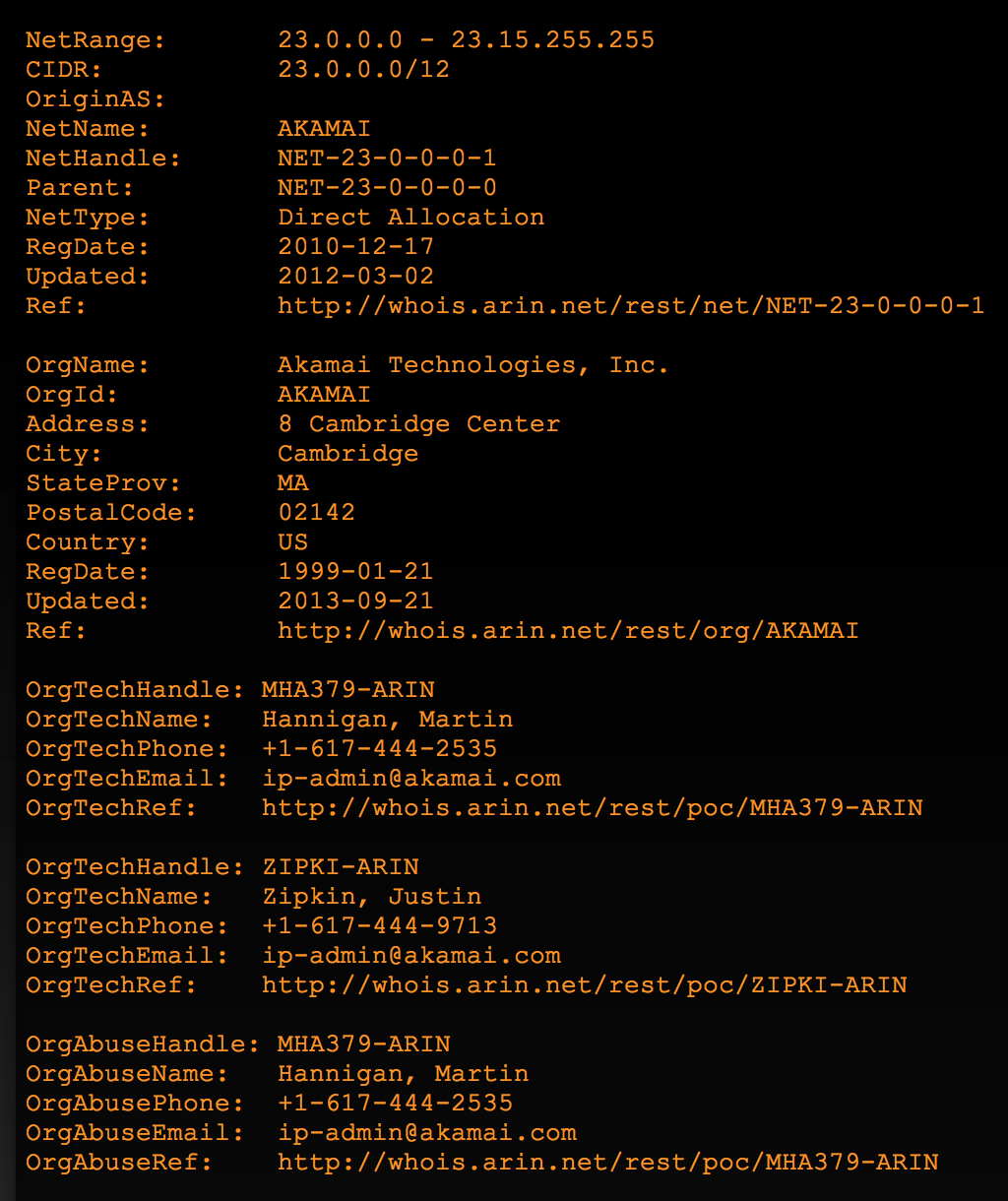
Depending on who hosts the site, the NetRange may be considered “in scope” and prove useful a future DNS reverse lookup. As you can see here, the NetRange is owned by Akamai, a large CDN. For the purposes of this demonstrative exercise I’m not going to pursue the IP range any further.
Google Searches
The next thing I’ll usually do is a Google subdomain search. For example, let’s say our site of interest is still healthcare.gov. My first search might be:
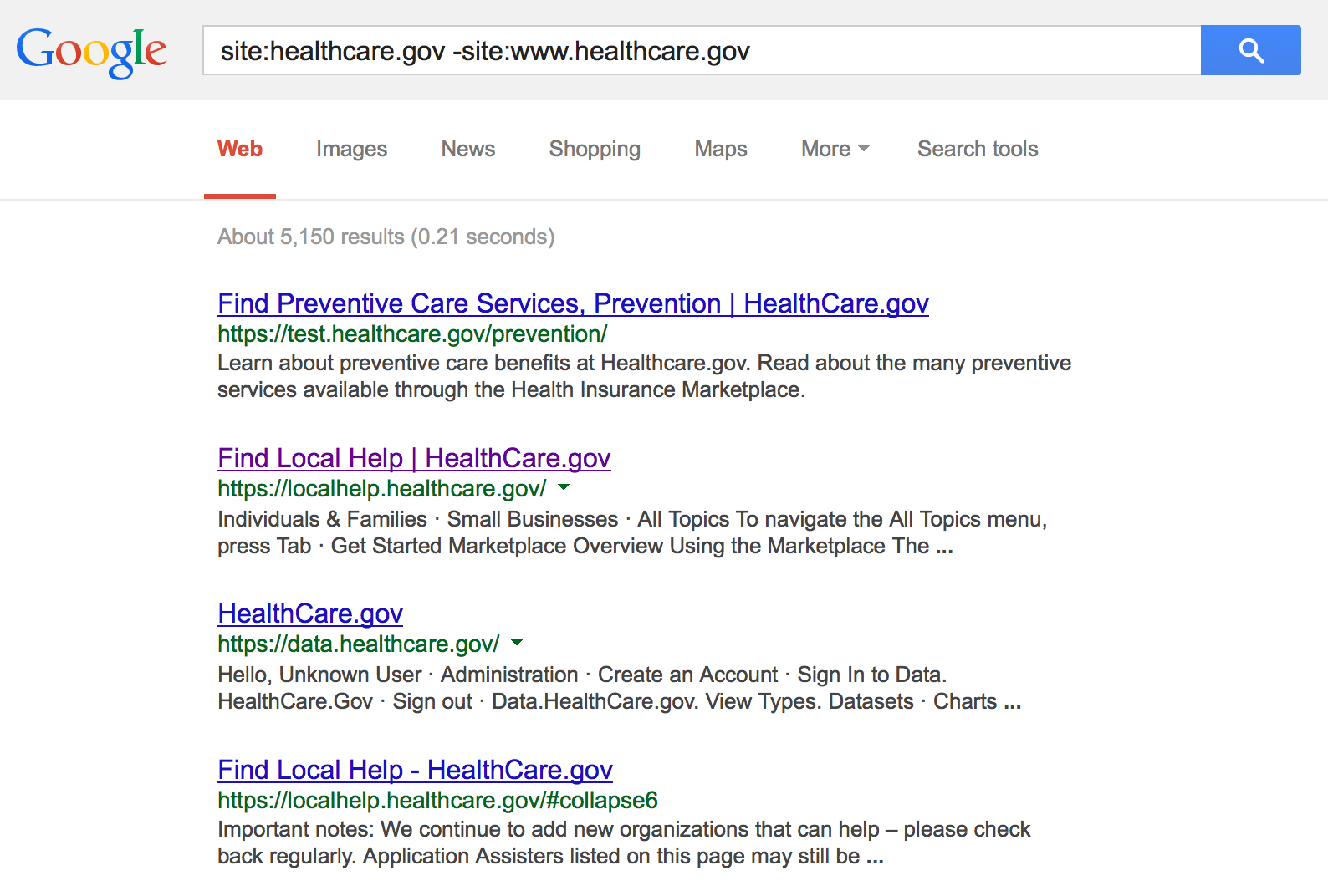
Note: if you’re searching a domain that is not prefixed by “www” (e.g. http://domain.com) but want to exclude this parent domain and only see results for the subdomains, you can try this Google search: site:*.domain.com
Rather than combing through all of the results, as you identify new sub-domains you can remove them from scope using an updated Google search query. For example, referencing the above screenshot, the next query you perform could be:
site:healthcare.gov -site:www.healthcare.gov -site:test.healthcare.gov -site:data.healthcare.gov -site:localhelp.healthcare.gov
This would remove the already-identified domains from the search scope and only return results from other sub-domains. Keep in mind there are other ways to modify your query (such as -inurl) which can lead to different search results.
Ultimately this exercise identified the following subdomains for *.healthcare.gov:
- test.healthcare.gov
- assets.healthcare.gov
- localhelp.healthcare.gov
- data.healthcare.gov
- finder.healthcare.gov
- finder-origin.healthcare.gov
- akatest.healthcare.gov
- finder.healthcare.gov
- spa.healthcare.gov
- search.healthcare.gov
- healthcare.gov
- chat.healthcare.gov
- search.imp.healthcare.gov
Obviously you would want to find out more about each of these domains but for now, the point of this exercise is simply to identify as many related domains as possible. That being said, the public-facing domains on this list containing the word “test” would certainly be of interest for further investigation!
Rinse, Repeat
Once you have a list of subdomains, you can work your way down the list, performing additional Google searches to identify other subdomains or related sites. As an example, let’s perform a Google search on search.imp.healthcare.gov
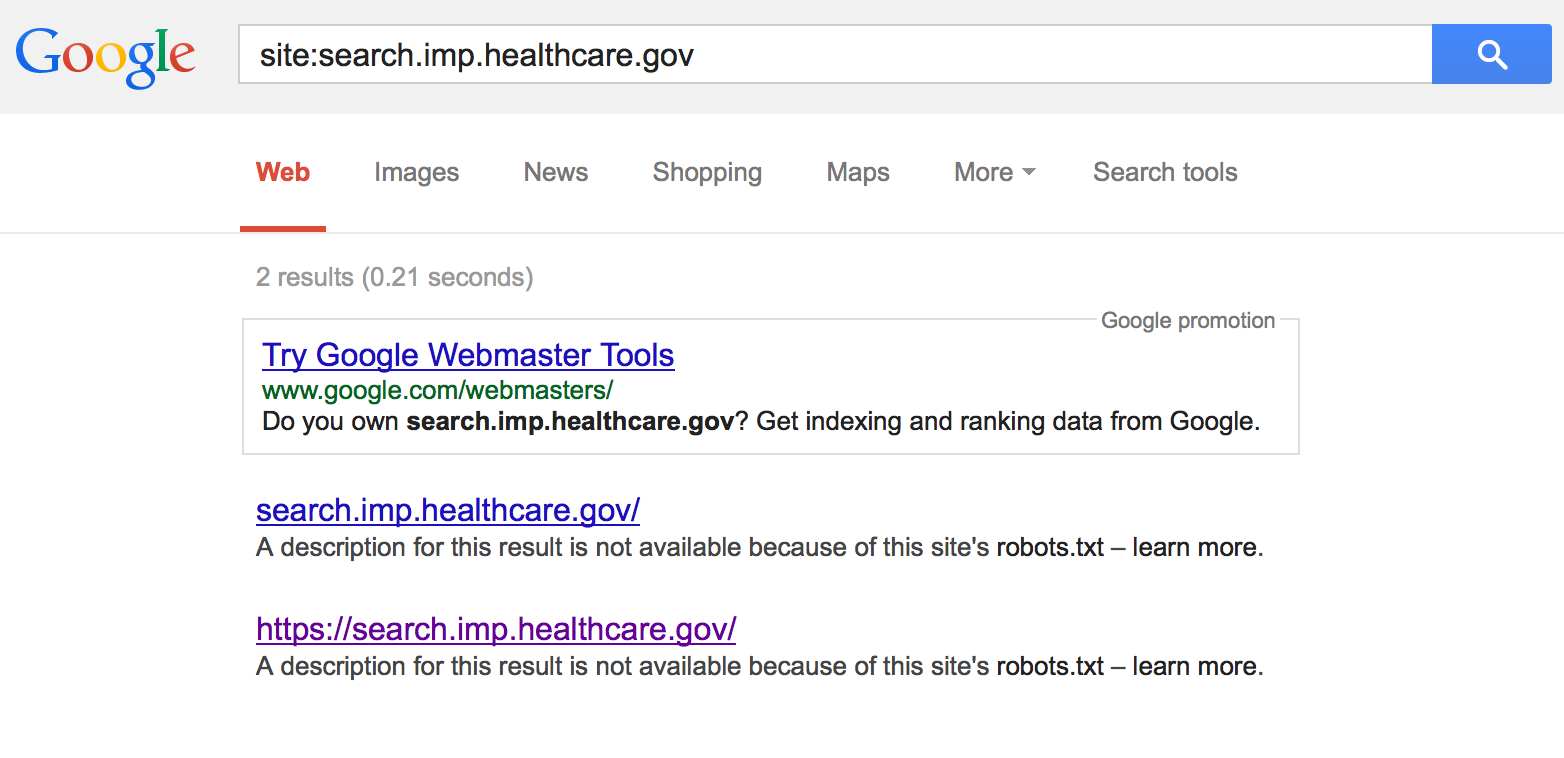
This reveals a Google custom search page that returns results in Spanish for a completely separate domain that we had not yet discovered (cuidadodesalud.gov).
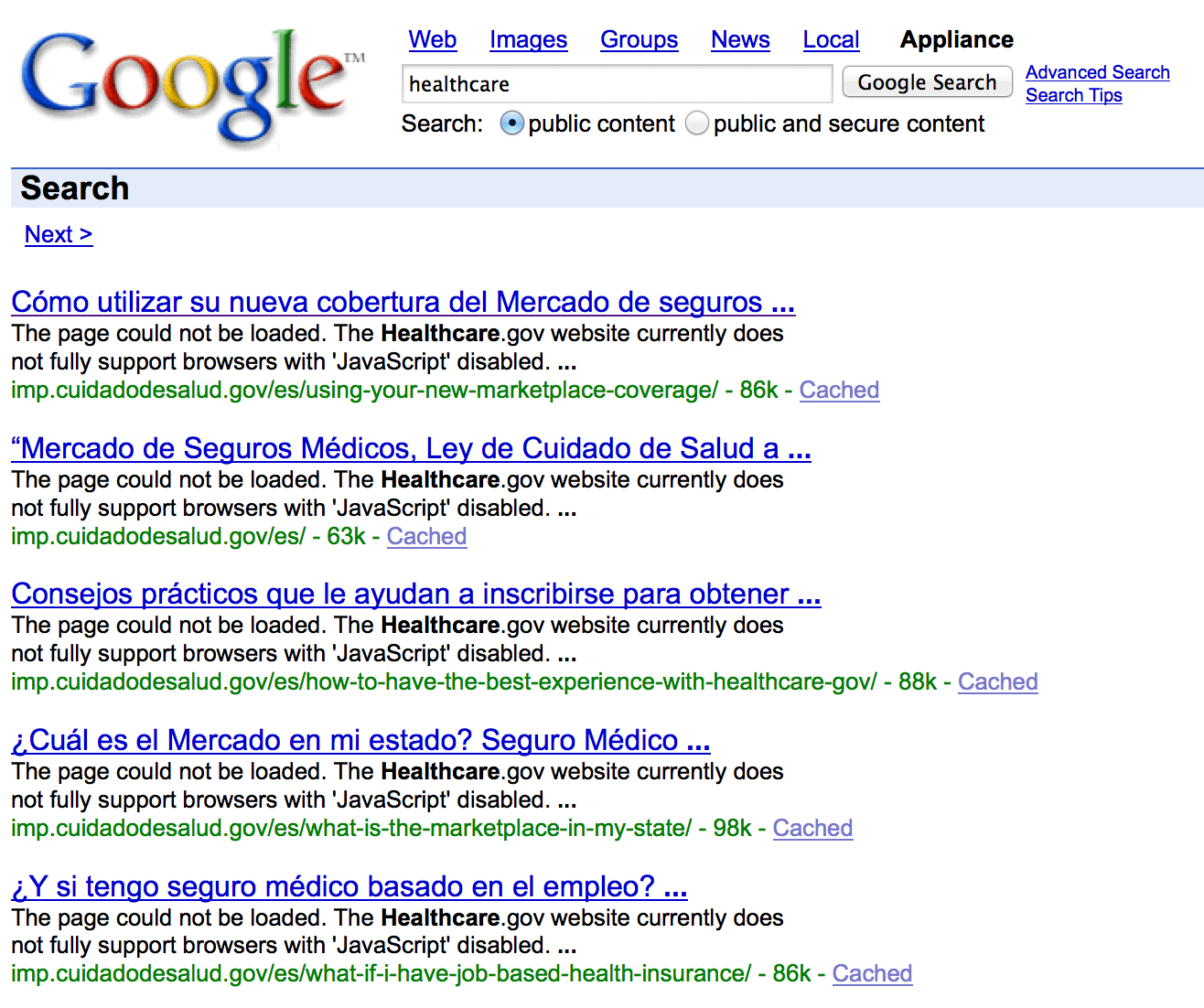
You can continue to perform these searches to get a clearer picture of your target organization’s web presence.
Netcraft
Netcraft is another useful tool for identifying subdomains. Below are the results for healthcare.gov from searchdns.netcraft.com

In this case, nothing new was found for this particular domain.
Browsing/Spidering
Another method of identifying subdomains is by simply browsing the site with an intercepting proxy. Here is an screenshot of Burp proxy with a host scope set to: ([.]*healthcare[.]*)|([.]*salud[.]*)
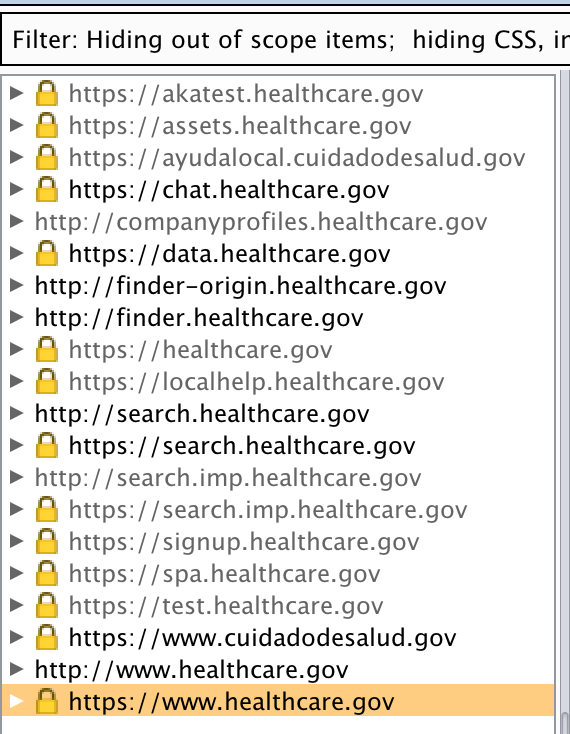
As you can see, browsing the site located a few more subdomains that weren’t identified via the Google search method. You may also use an intercepting proxy such as Burp to actively spider the site, automatically following each link to discover new content. Use caution, as automated spidering is “noisy” and can cause issues with authentication functions or inifinite loops. While proxies such as Burp can easily be configured to deal with such issues, I recommend against unrestricted active spidering unless you are conducting a sanctioned test. As an alternative, Burp proxy can be configured to use Passive Spidering (which I always keep enabled) to maintain a current site map as you manually browse the site.
You may also choose to download a site for offline viewing/parsing. There are several tools available including HTTrack and SiteSucker.
A word about some related active recon techniques…
The information collected thus-far would generally feed some follow-on, active reconnaissance DNS activities, namely forward/reverse lookups and zone transfers. Because they’re so closely related to the passive recon activities we’ve looked at so far, I’ll mention them briefly here.
DNS Forward and Reverse Lookups (Active Recon)
Once you’ve identified the various subdomains, you will also want to identify the associated IP address ranges. There’s several ways to do this (via Burp proxy, ping, etc) but I prefer to script a DNS forward lookup using the list of subdomains as input, and generating a list of IP addresses as output.
Here’s a very basic CLI example for a single domain (loop through your subdomain list to make it more efficient):
root@kali:~# host sub_domain | grep ‘has address’ | awk ‘{print $4}’
Pay attention to the discovered IP addresses and whether they fall within the net range(s) already identified via your Whois lookup. If not, perform additional Whois lookups to see if the associated net ranges are of interest. For any newly identified IP addresses, perform a reverse DNS lookup to determine the domains to which they belong.
Zone Transfers (Active Recon)
In order to perform a DNS Zone Transfer, you obviously need a list of DNS servers, which you can get from a simple Nslookup.
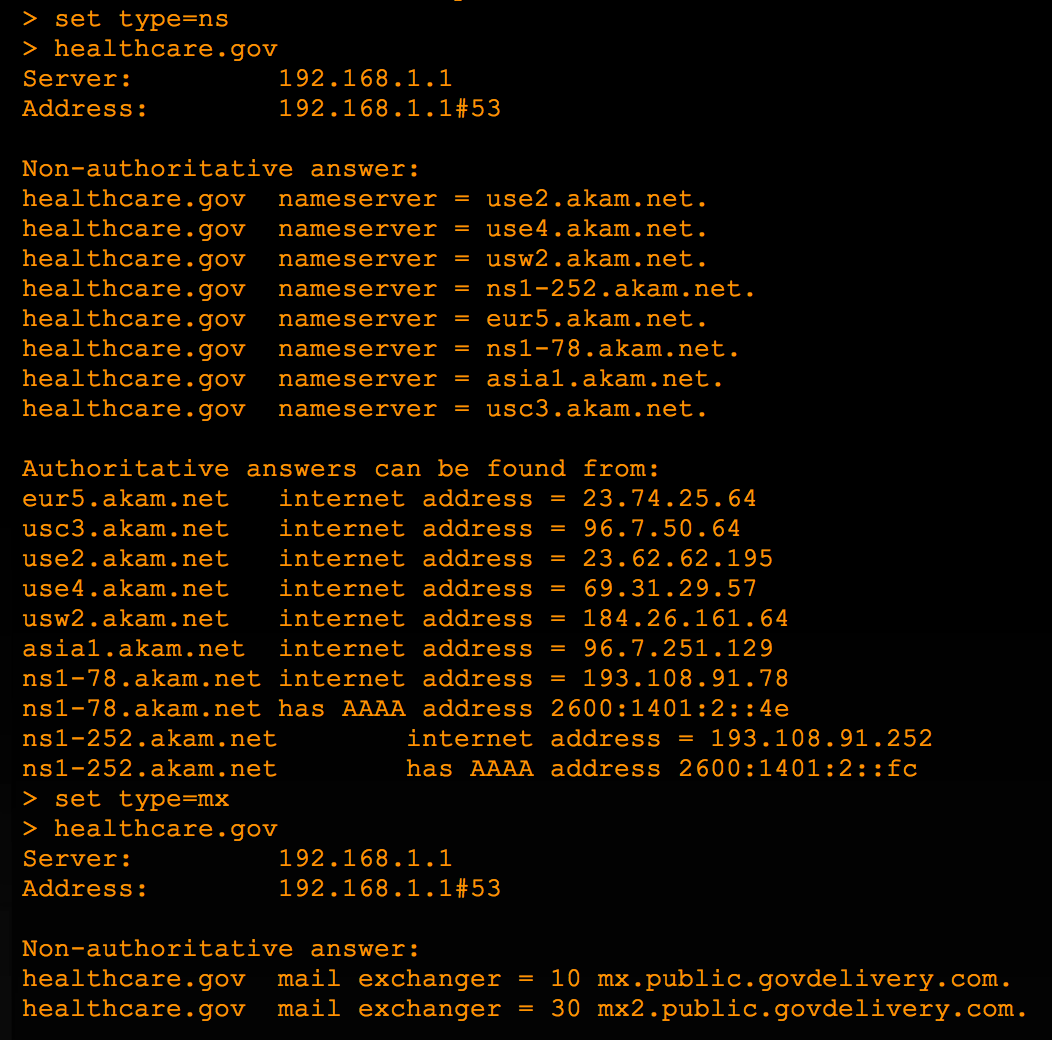
There are also websites that can provide the same information (and more) with a single query such as http://www.intodns.com. With a list of DNS servers you can attempt a zone transfer on each, using dig or host:
dig @
Per Cisco Press, article Penetration Testing and Network Defense: Performing Host Reconnaissance
“Simply performing an NSLookup to search for an IP address is passive, but the moment you begin doing a zone transfer using some of these tools, you are beginning to do active reconnaissance”.
For this reason and due to the debate surrounding the legality of Zone Transfers (perform a Google search for past legal precedent in North Dakota), I will not demonstrate this technique.
Other tools
There are alternate tools available that will automate most, if not all this DNS discovery for you (both active and passive activities). Some are available in Kali (dnsenum.pl, maltego) and others are available as browser plugins (check out the passive reconnaissance plugin for Firefox). Here is a screenshot from a very powerful tool called Maltego.
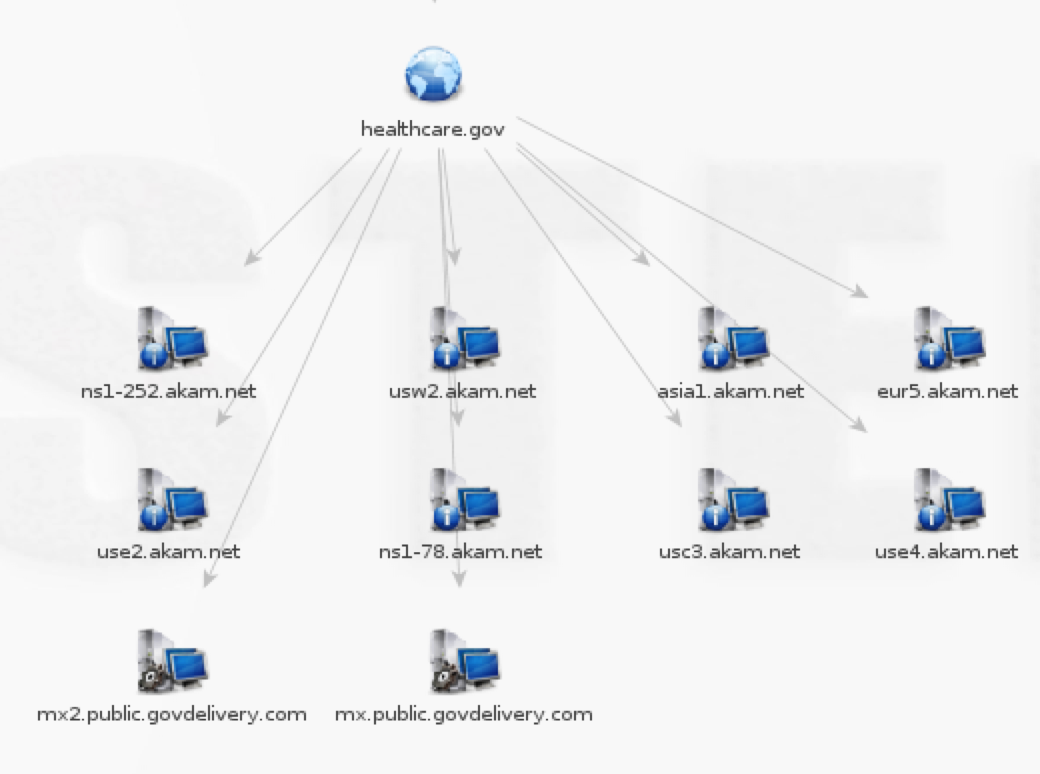
DNS enumeration example from Maltego
Here’s Passive Reconnaissance plugin for Firefox
Just because some of the previous activities fall under the umbrella of active reconnaissance doesn’t mean you can’t obtain their results passively. You may find enumeration scan results already posted to the public domain on sites such as Pastebin.com such as the following Nmap scan results and DNS info for healthcare.gov.

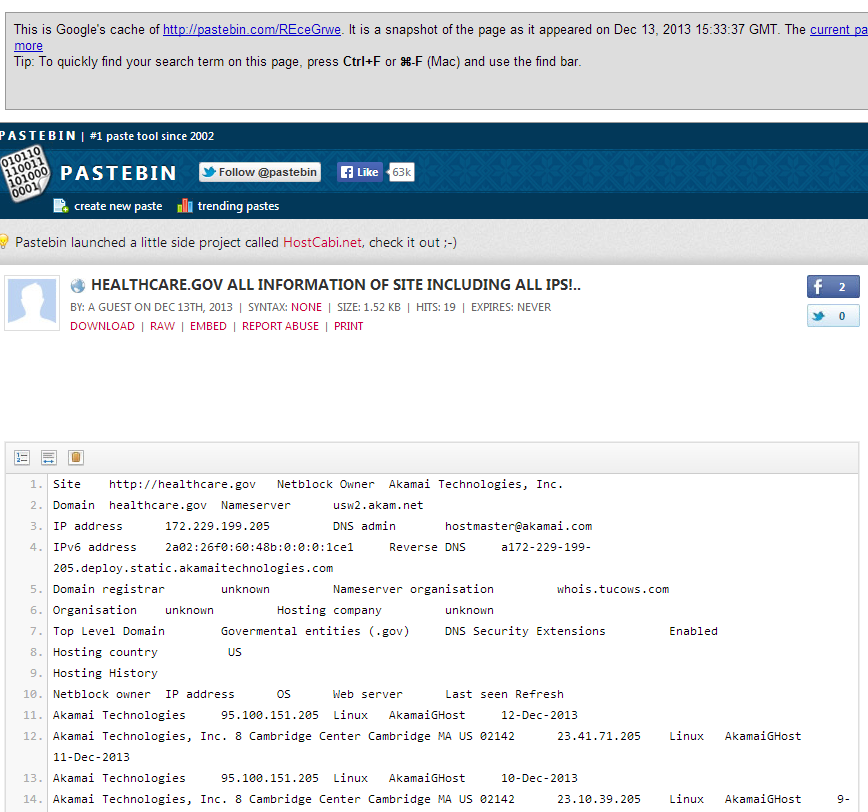
Pastebin is a great resource for passive information gathering. I find it easier to search Pastebin via Google (site:pastebin.com
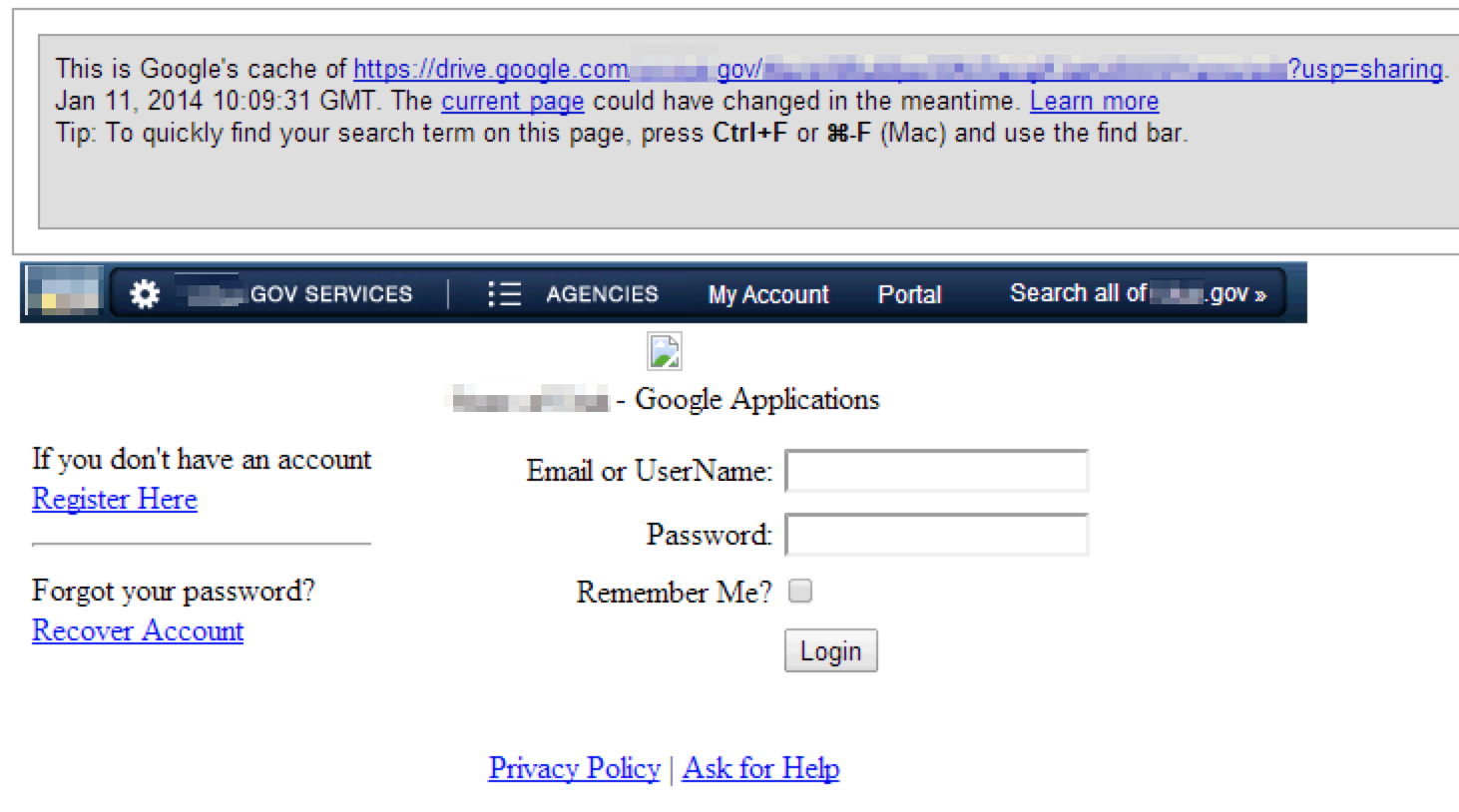
A word about Google cache…it’s fantastic to be able to view content of a site without actually touching the site itself, especially when you’re viewing potential vulnerabilities. Keep in mind that not all content is cached by Google, specifically media such as images and video. If you truly want to view a text-only, cached version of a page, be sure to include the &strip=1 parameter in your request.
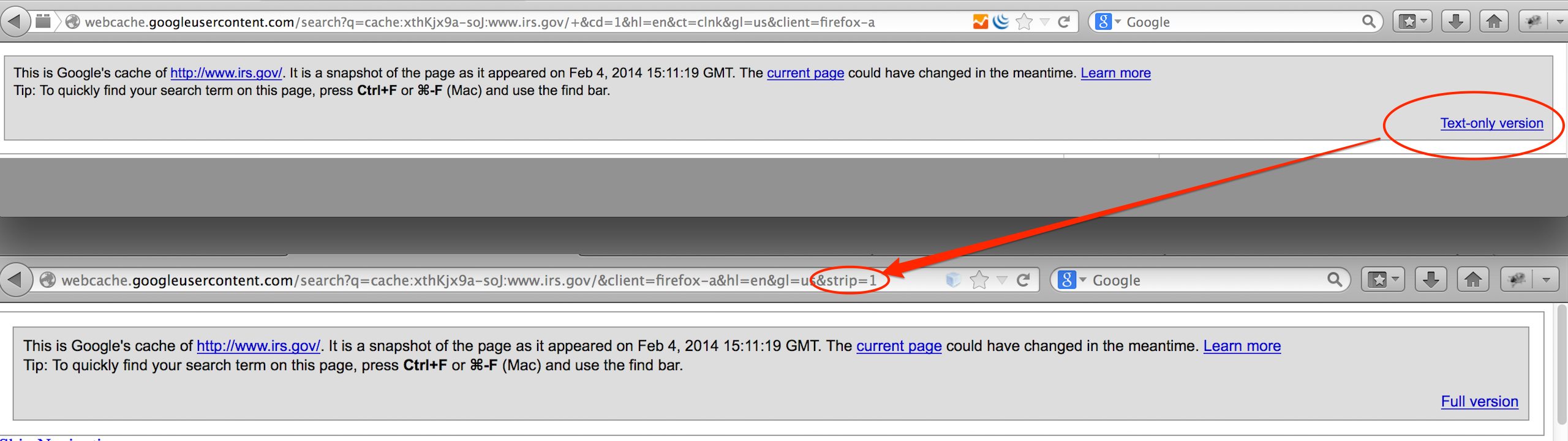
I use a quick-and-dirty method via Burp match and replace to force a text-only cache request:
![]()
Identifying Related External Sites
Identifying externally linked sites can be valuable as they often involve bi-directional data transfers of interest. Simply loading healthcare.gov in a browser configured to use BurpSuite as an intercepting proxy (without a restricted scope) reveals plenty of additional sites that send and/or receive site content.
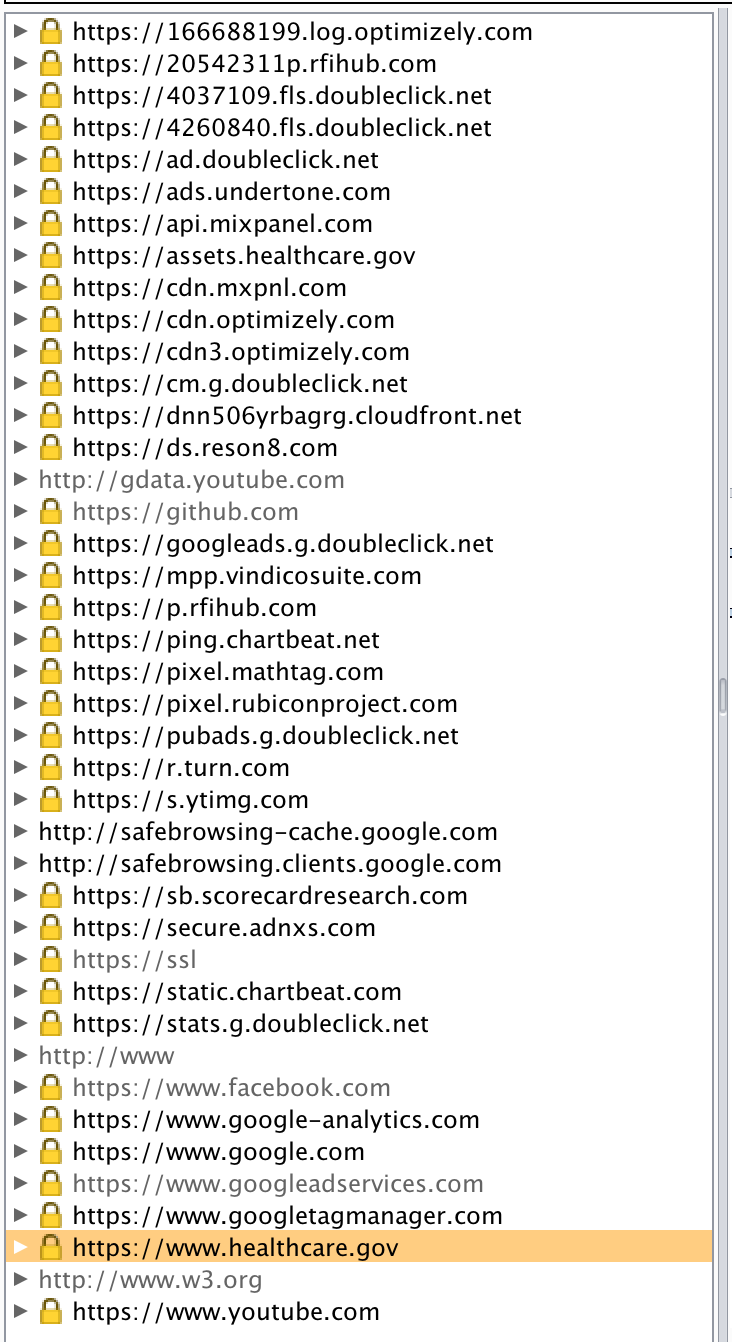
If healthcare.gov were the subject of your data gathering exercise, it would be important to understand the relationship (and associated data flows) between these sites. You may choose to rule out known sites such as doubleclick.net or google.com and use the scoping feature in Burp to remove these domains from view.
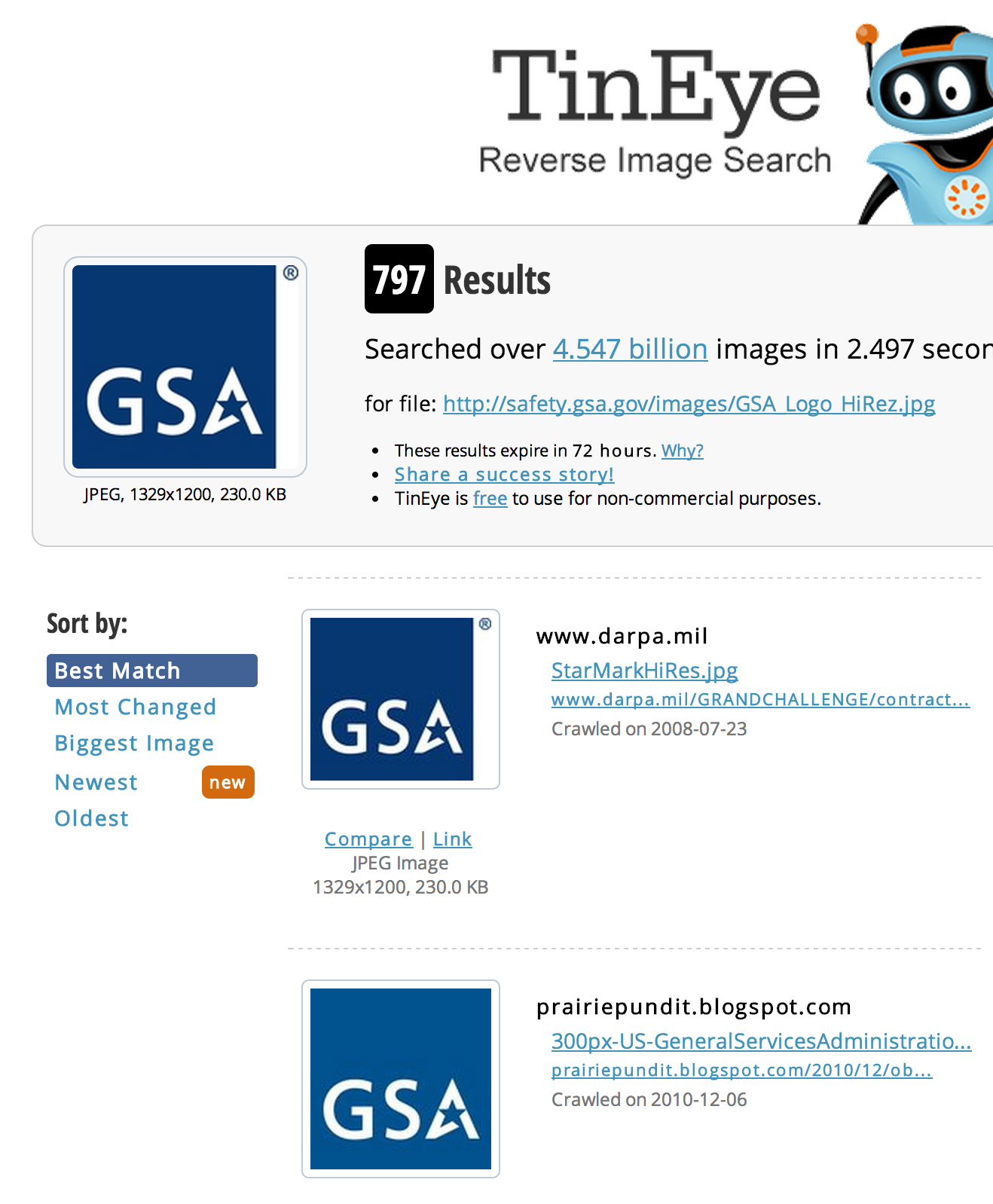
Another way to identify related sites is to use an image matching tool such as TinEye. Here, I’ve grabbed the logo of the General Services Administration from its website and using TinEye, have identified other sites that reference the same or similar picture. This may identify direct or indirect organizational relationships of interest depending on the scope of your assessment.
Just a quick note about documentation … organization is a key component to a successful information gathering effort. I usually like to keep a working spreadsheet that documents my finds. It may be as simple as the following to start:
| URL | IP | Net Range | Notes | |
| Target Domain | target.gov | 10.1.1.1 | 10.1.1.0 – 10.1.1.255 | |
| DNS Servers | dns1.target.gov | 10.2.1.1 | 10.1.1.0 – 10.1.1.255 | Master |
| dns2.target.gov | 10.2.1.2 | Slave; zone transfer enabled | ||
| Mail Servers | mx1.target.gov | 10.3.1.1 | 10.1.1.0 – 10.1.1.255 | |
| mx2.target.gov | 10.3.1.2 | |||
| Subdomains | sub1.target.gov | 192.168.1.1 | 192.168.1.0 – 192.168.1.255 | Exposed Test Infrastructure |
| sub2.target.gov | 192.168.2.1 | 192.168.2.0 – 192.168.2.255 | ||
| sub3.target.gov | 192.168.3.1 | 192.168.3.0 – 192.168.3.255 | ||
| External Sites | ext.gov | 10.200.1.1 | 10.200.0.0 – 10.200.255.255 | Partner organization; data sharing |
| ext.com | 172.16.1.1 | 172.16.1.0 – 172.16.1.255 | External host provider |
As you collect more information (people, technologies, vulnerabilities), you can add columns and tabs to the spreadsheet to organize your data.
Identifying People
Another important task of Passive Reconnaissance is identifying the people related to your target organization (employees, contracted third-parties, etc.) which might prove useful for a subsequent social engineering activity.
Consider the following sources when attempting to identify target organization personnel:
- Company website
- Third-party data repositories
- Tools such as Maltego
- Message boards
- User Forums
- Document metadata
- Social media sites
Company Website
Some organizations publish organizational charts and/or phone directories of varying completeness (such as this one from the IRS). These often contain names, titles, phone numbers, office addresses, and more.
If you download the site for offline viewing, you can easily grep the contents for email addresses. Alternatively, you could use the search function of Burp Pro to find all email addresses of websites you’ve spidered via regex.
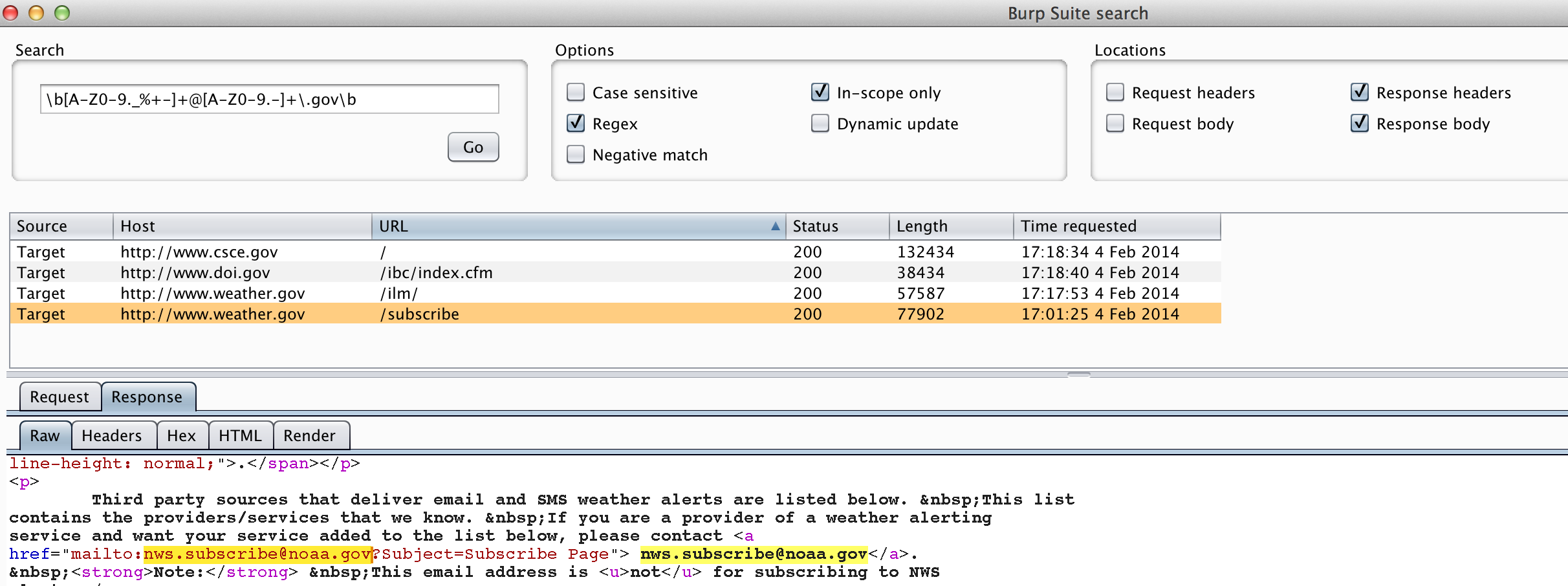
Third-party Data Repositories
If the company website doesn’t have any useful employee information, third-party sites such as Cogmap.com may have relevant organizational charts. Another good source for gathering employee data are sites that specialize in gathering marketing data such data.com. Here’s a small sample of a much larger employee listing for the IRS.

As you can see, it identifies a user’s social media presence and related websites and also provides the ability to search public records (for additional fees).
Maltego
Maltego provides the ability to look up email addresses based on a given domain. Here’s an example using nasa.gov (note: for demo purposes, I limited the results to 12, but the max in my pro version is 10,000)
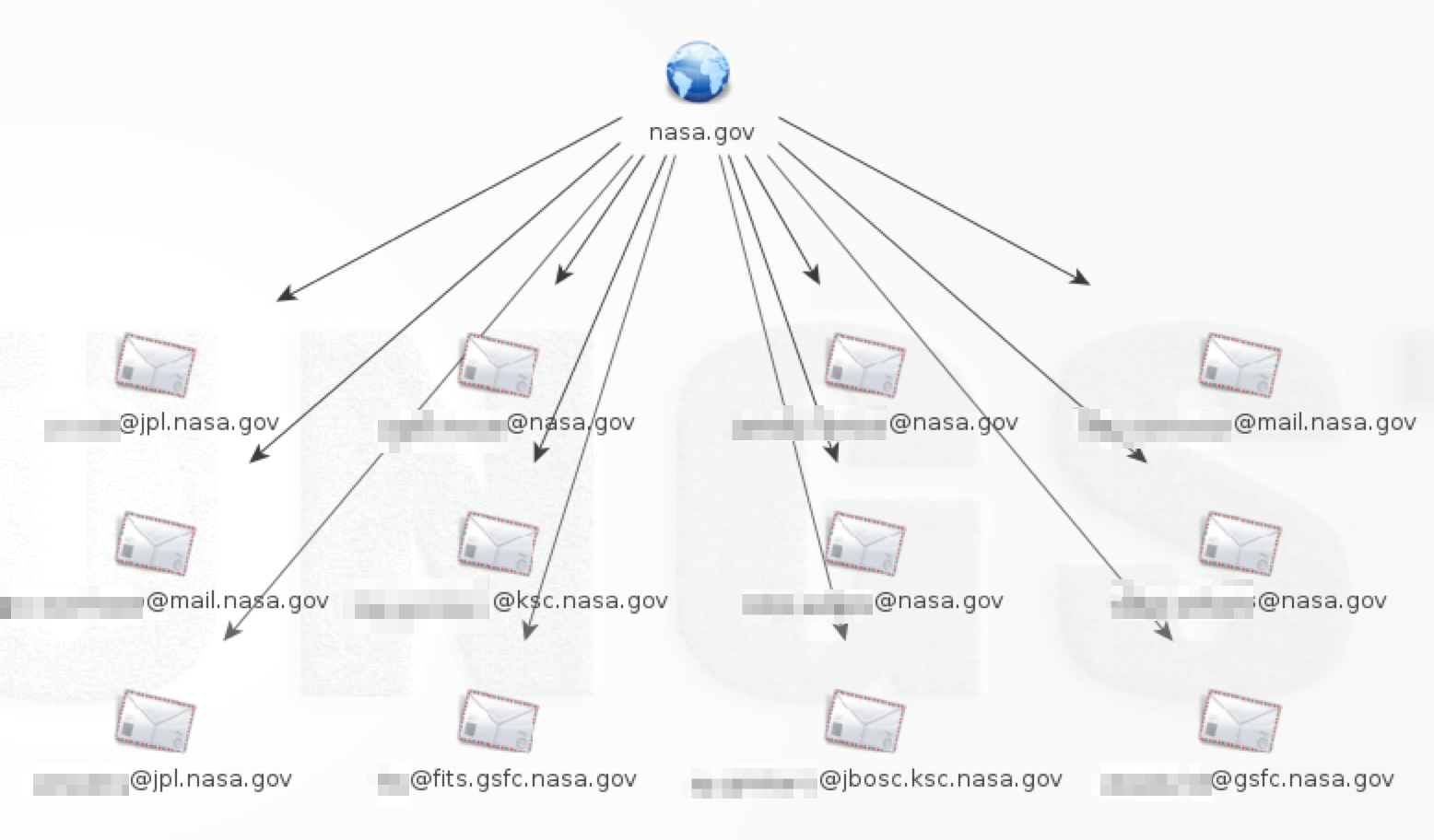
You can perform further ‘transforms’ (Maltego term) on each of these email addresses to identify the person’s full name, or find related email addresses, phone numbers, websites etc.
Message Boards and User Forums
Message boards and user forums are also good sources to identify potential targets for social engineering. You might find employees airing grievances or using technical message boards to troubleshoot problems. They might name their organization directly, leave their signature block in an email post, use their work email for their forum contact, or include other identifying information in log dumps, stack traces, source code, etc.
Here’s a basic example from Google forums that reveals a person’s name and email address as well as specific products and versions that might be in use within their organization — information that could prove useful for targeted vulnerability testing.

Document Metadata
Publicly-posted documents are a great source for identifying people (as well as sensitive information). Even companies that don’t publish employee directories may forget to strip identifying metadata from their documents. For this demo, I’ll focus on XML-based office documents (docx, xlsx, pptx) as they can provide a wealth of data. Each of these types of documents contain metadata that potentially identifies the author, the person that last modified the document, and the organization name. They can reveal full names as well as usernames. These documents also frequently contain email addresses and phone numbers within their content. You can download and manually review each document but it’s much better if you can automate the task.
I’ve written a quick demo script to illustrate how easy it is to extract this information. If you want to try it (I’ve tested it briefly on Mac/Ubuntu/Windows) I’ve made it available below.
The first step is to download the files of interest. You may choose to download all available files for a particular domain or maybe focus on those that contain specific keywords:
site:<target_site> filetype:xlsx | filetype:pptx | filetype:docx “salary”
Then, simply dump all of the office files you’ve downloaded to a folder and use that location as the sole argument: metasearch.py <folder_path>
The script will generate an output as follows:
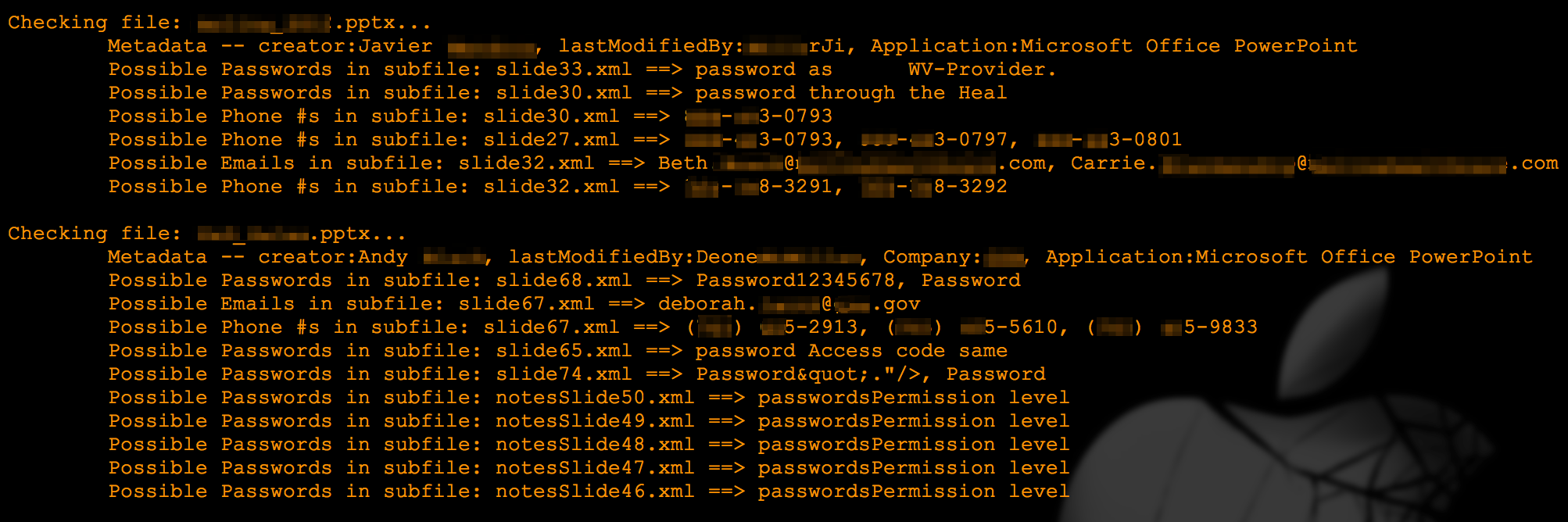
It will also create two folders within the target folder — “found” and “notfound” — to sort the files based on whether any interesting data was discovered. For each file placed in the “found” folder, it will create another folder corresponding to the file’s name in which it will place the original file plus a copy of each xml sub-file in which it found interesting data. For example, if you scan a PowerPoint file named “file1.pptx” and interesting data is found on slide 2, within the “found” folder you will see another folder called “file1” and within that folder, a file titled “slide2.xml”.
In its current demo state, the script looks for personal identifying information such as document metadata, phone numbers, email addresses. It also has some rudimentary SSN and password detection (the latter solely triggered by the the keyword “password”). For example, in the following screenshot you can see one of the possible passwords discovered in the original pptx file.

If you compare the xml content with the script output, you’ll see the password discovery function extracts the text immediately following the word password (for context) and strips out the xml tags. This content searching functionality is pretty rudimentary and locating documents based solely on their content can easily be accomplished via Google searching. I script solely for functionality not efficiency, so feel free to refine, remove or add features as desired. All I ask is you maintain the original author credit and do not use the script for any commercial purposes.
Writing your own metadata extractor does provide you with the flexibility to add additional functions and search for specific content but if you’d prefer not to, there are plenty of other, more feature-rich Metadata search tools out there including OOMetaExtractor, Metagoofil, Metadata Extraction Tool, and FOCA which helps passively map internal network technologies simply by analyzing document metadata.
Gathering Additional Personnel Details
Let’s say at this point you’ve been able to generate a large list of single data points for people of interest — an email address or phone number but no name, a name but no email or phone, etc. To gather additional data, I will generally turn once again to a Google search.
For example, the pptx file downloaded earlier was edited by someone named Deone XXXXXX. Given the domain in which the document was found, we have an idea of where she works. A subsequent Google search easily uncovers her job title and contact information.
Yes, this person’s info is publicly posted but I didn’t see a reason to include her full contact details here.
Social Media
Taking it a step further, we can search social media sites to gather additional job-related and personal information that can be useful in targeted pretexting/social engineering attacks or password guessing/password reset attempts.


Here we’ve gone from only having a person’s name found in the metadata of a document to obtaining her professional contact information as well as two social media profiles (and any other useful data that will come from that). I encourage you to investigate the various available social medial APIs. While most restrict searchable content, rate limit requests, and limit the number of responses, you still may find them useful. I’ve written several scripts designed to quickly search data from multiple social media sites (Facebook, Twitter, LinkedIn, etc) and it’s certainly a time-saver if you plan on doing it often.
Maltego is another good tool to quickly gather more detailed personnel information. Below you can see abbreviated results of a search for my own name, listing related websites, social media accounts, verified email addresses, etc.

People-Search Sites
Sites like Spokeo and Pipl are great for gathering information about people and provide access to phone numbers, email addresses, addresses (past and present) and even family tree information (some services only available for a fee).
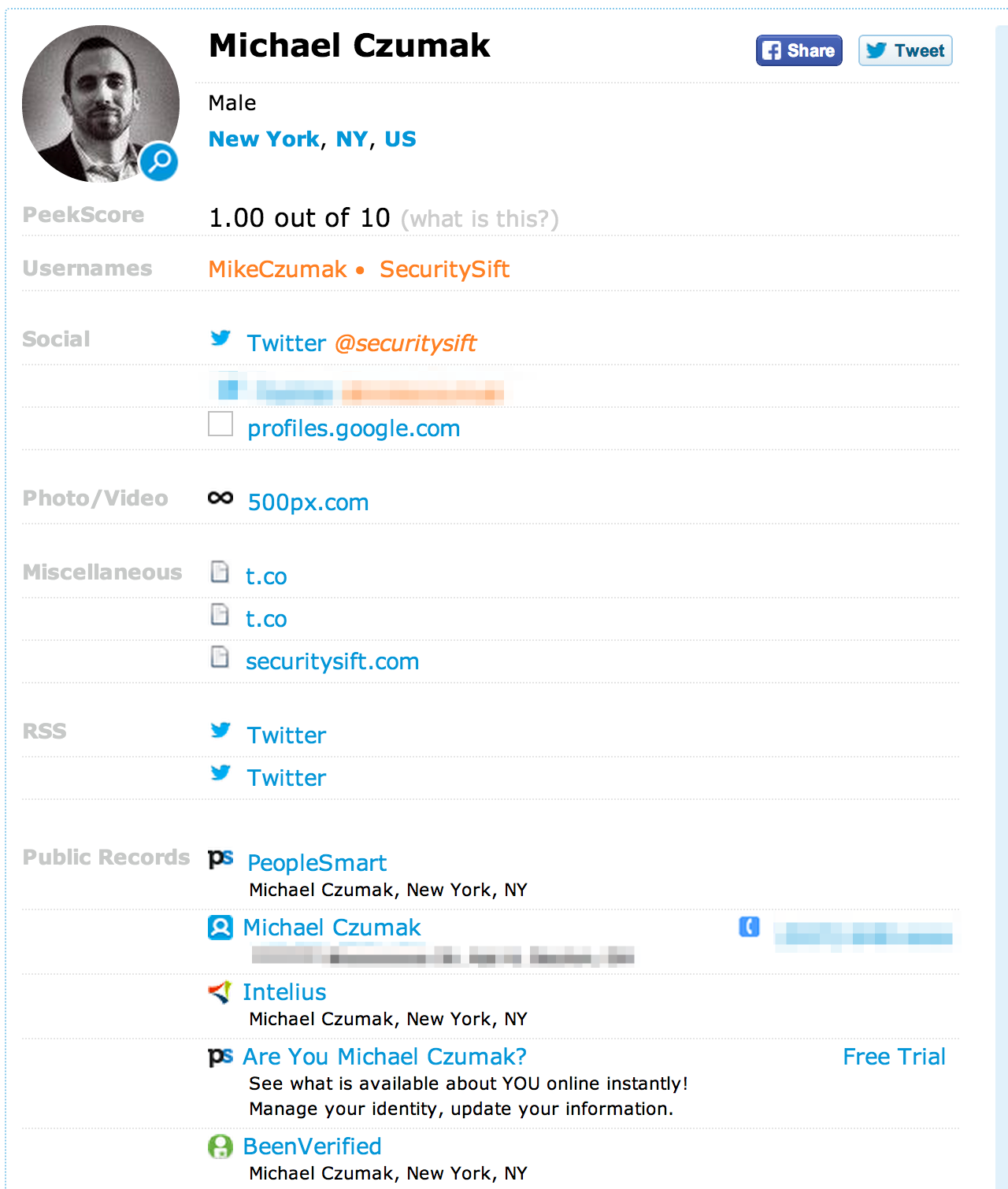
PeekYou is another useful site for finding out information about a given person. Here’s an example using my own name:
Financials
Depending on the type of company you’re targeting, you may be able to reference publicly available financial reports to identify executives or other key personnel. Some good resources include SEC’s EDGAR database and Reuters.
As you’re gathering all of this data, remember to keep it organized. Consider recording at a minimum the following data points in a table or spreadsheet for each person of interest you identify:
- Name
- Email Address(es)
- Phone Number(s)
- Address
- Position/Title
- Social Network Profiles
- Other related websites
- Notes
So far, you’ve developed a scope for your reconnaissance by identifying the website, sub-domain(s), DNS/Mail servers, IP addresses. You’ve also identified some potential social engineering targets. Before we move on to website content and vulnerability discovery, it’s important to identify the major technologies employed by the site(s) in scope.
Identifying Technologies
Identifying the technologies in use by an organization is fundamental to finding potential vulnerabilities. Knowing that an organization runs an outdated or unsupported operating system or software application might be all that you need to develop a working exploit and get a foothold in the network.
You can ID technologies from many sources including:
- File extensions
- Server responses
- Job postings
- Directory listings
- Login splash pages
- Website content
- Public acquisition records
- Shodan
- Document Searches
File Extensions and Server Responses
As you’re navigating the target site(s), be sure to document anything that might indicate which technologies are in use. Pay particular attention to file extensions, HTML source, and server response headers. For example, the following site runs on ASP.NET which would indicate it is likely hosted on an MS IIS infrastructure.

Browse the site, and examine the server response with an intercepting proxy.
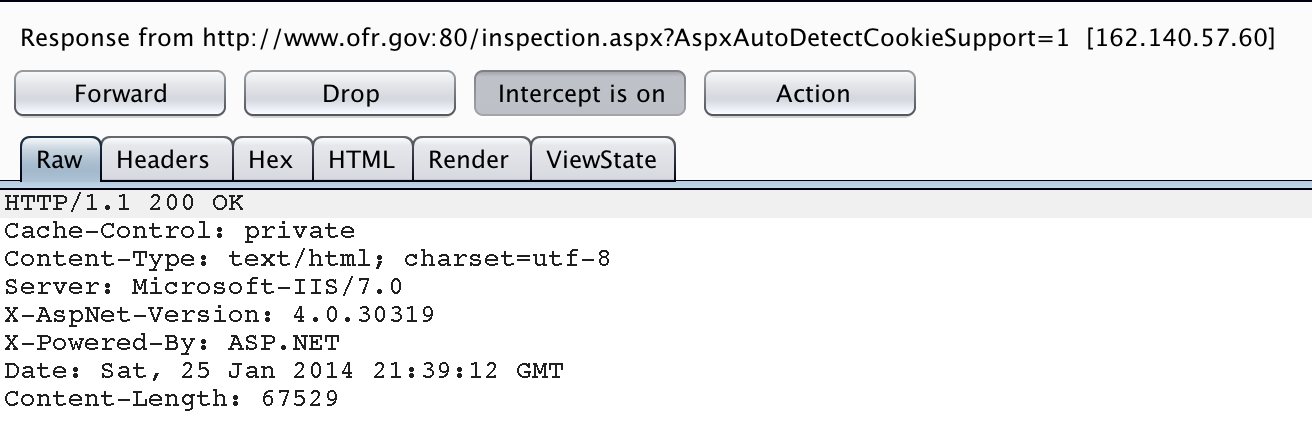
As expected, the site is hosted on an IIS server. From the server response we get the specific version of IIS and .NET, which can be useful in identifying potential vulnerabilities. Remember that server response headers can be modified by the system administrator so they’re not 100% reliable but they are a good data point to take note of.
Job Postings
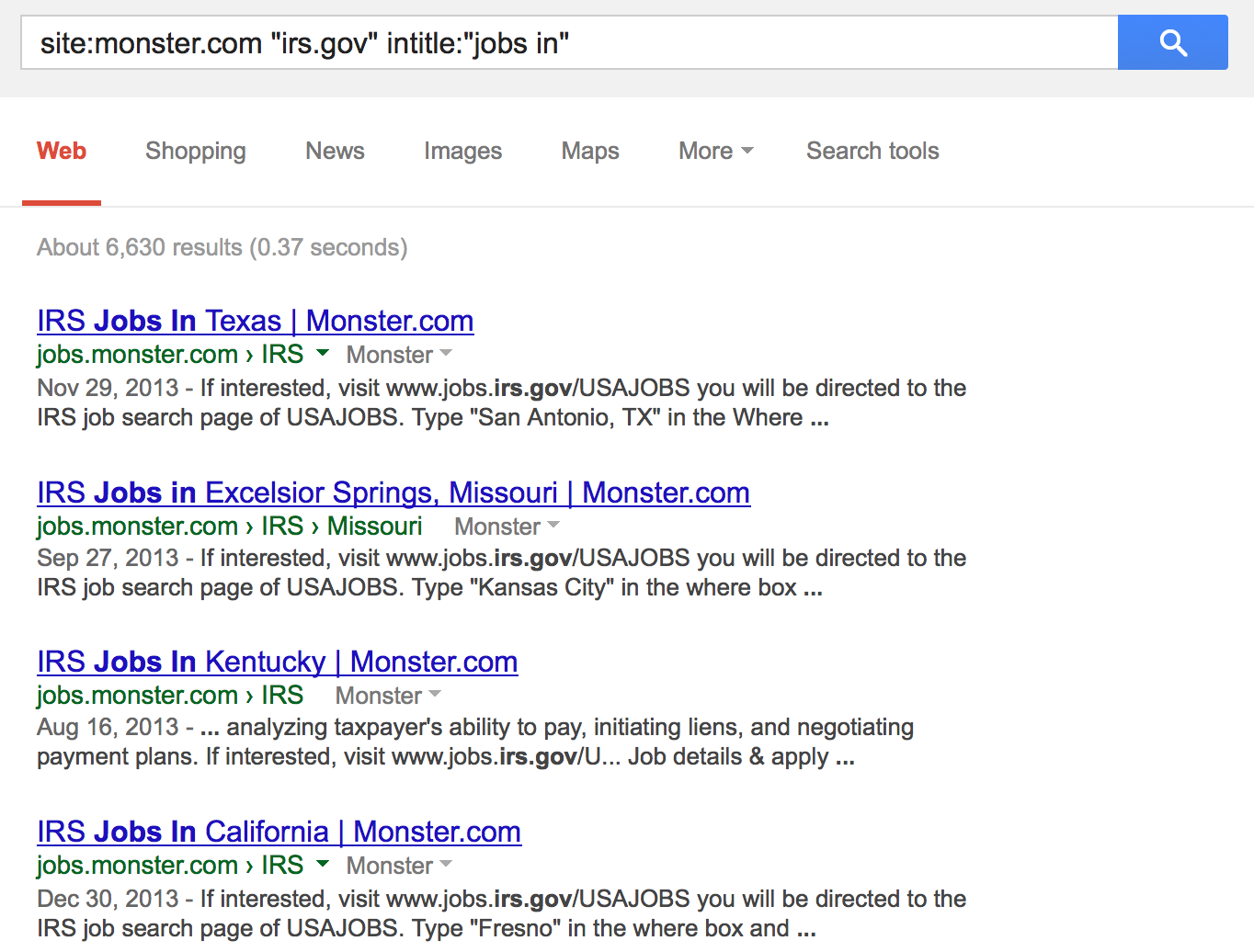
Another good source for discovering technologies are job postings. Organizations use sites such as LinkedIn, Monster, USAJobs, and others to advertise open positions and these advertisements often reference the specific technologies associated with the job.

Google is a good tool to search these job sites. Be sure not to discount closed job postings or cached results — the job may no longer be available but the technology may still be in use.
Directory Listings, Splash Pages, and other Clues
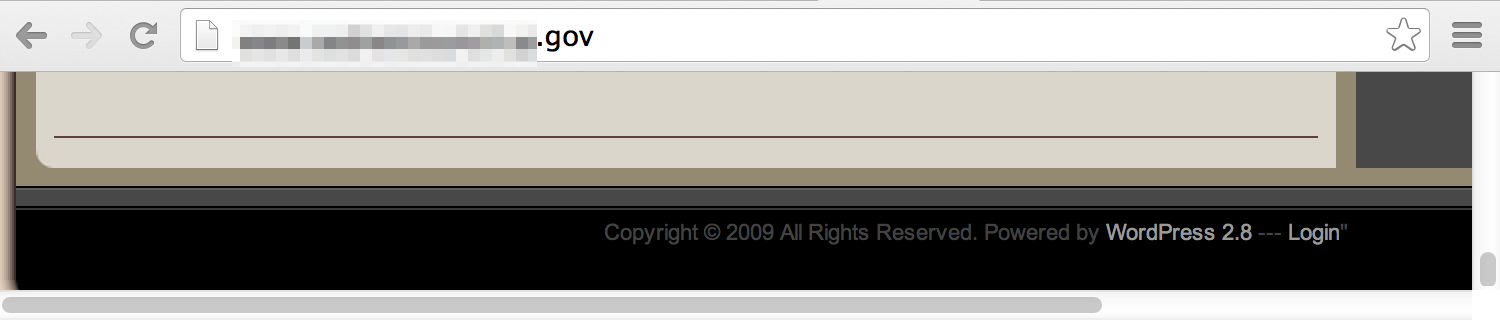
Various technologies have “signatures” that make them relatively easy to find with a Google search. For example, WordPress and similar content management tools tend to have “Powered by …” within the page footer.
A simple Google search can uncover these: site:<target_site>”Powered by”
![]()
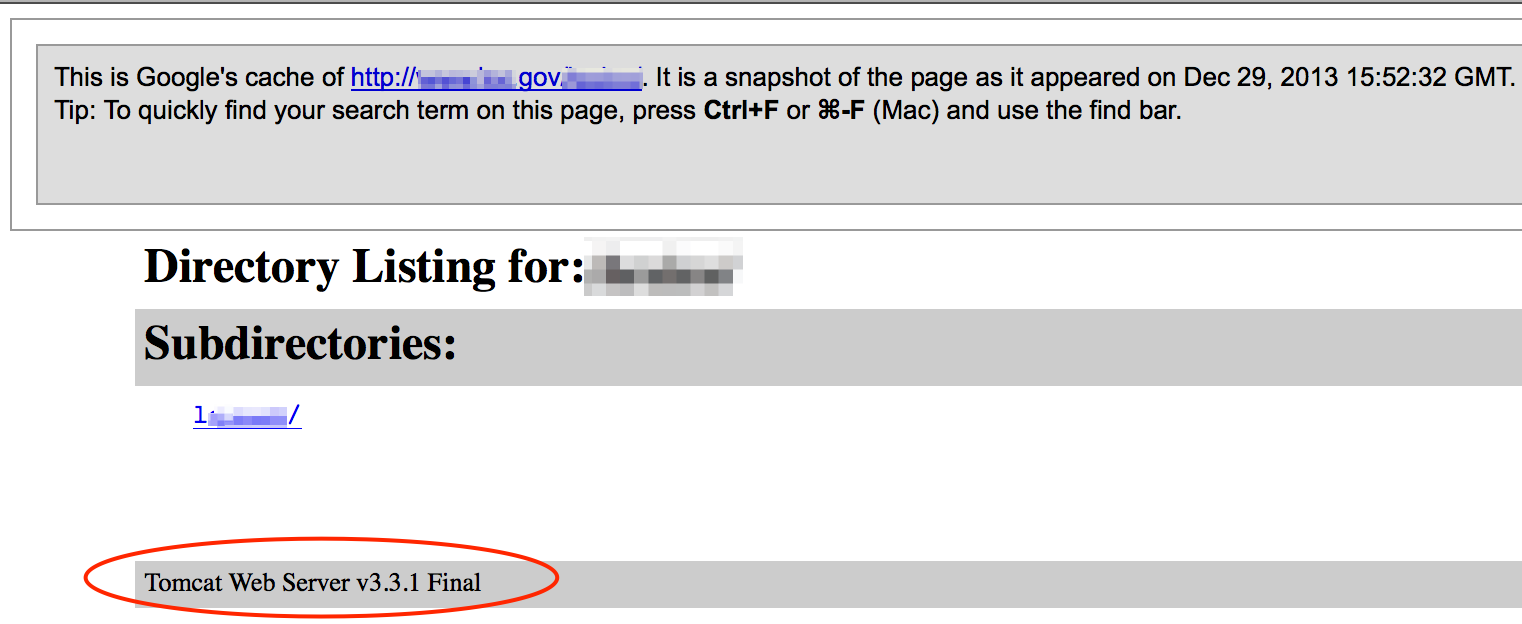
Directory listings often display the web server version in the page footer.
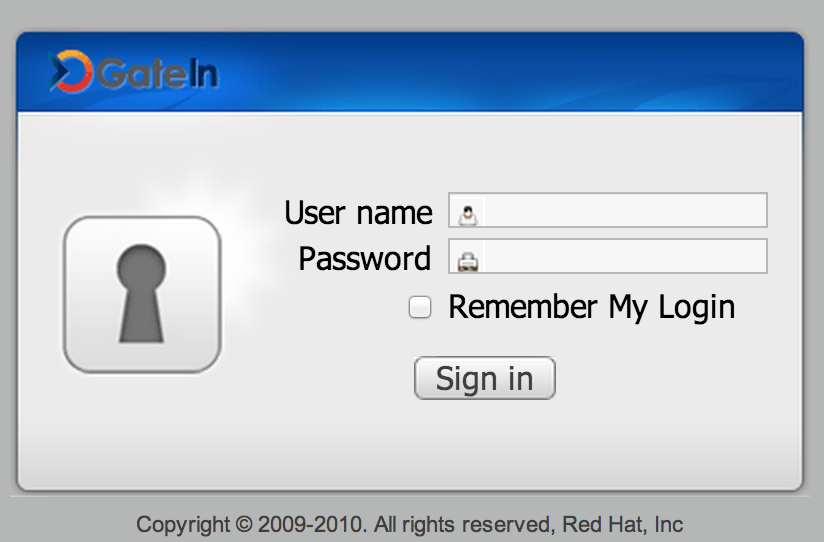
As you identify portals, login functions, and other pages of interest, the technologies may also be prominently displayed in standardized banners, icons, footers, etc.
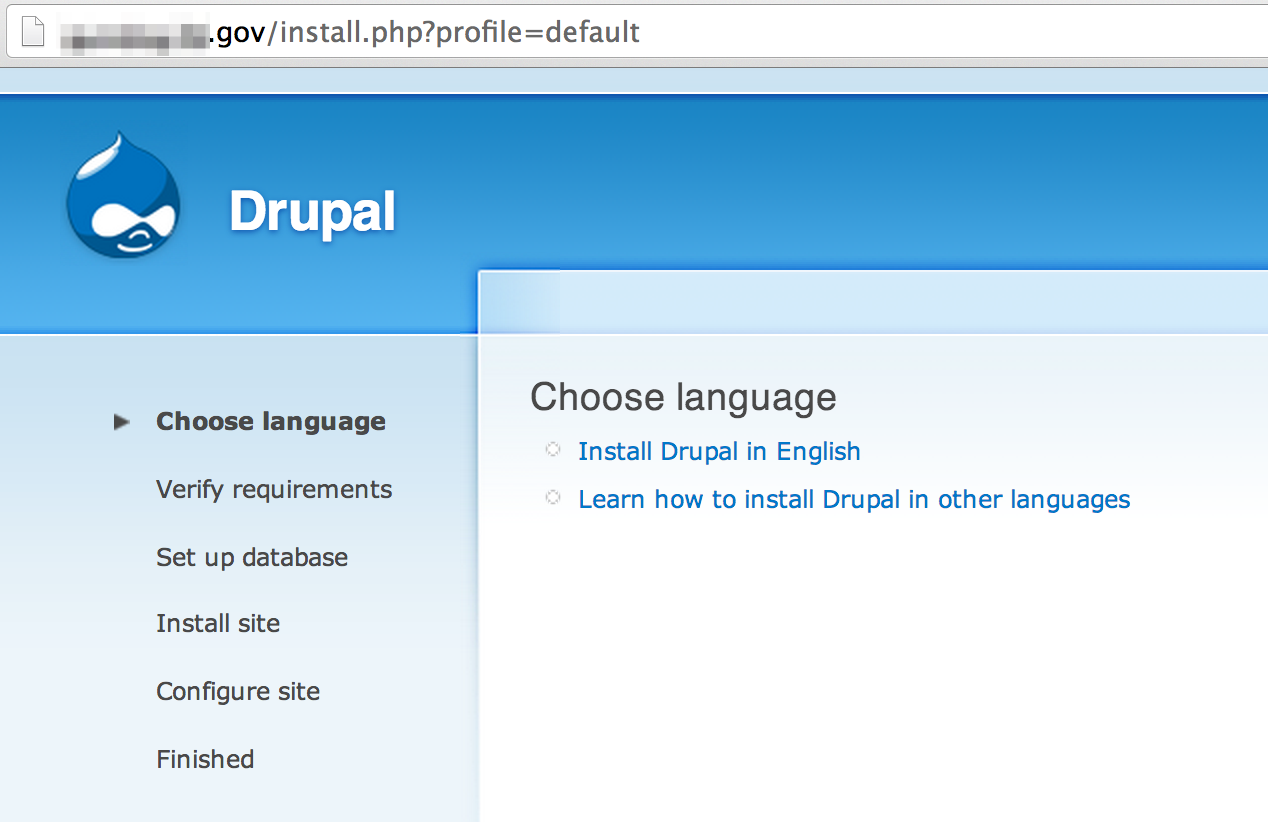
While identifying technologies you may also uncover potential vulnerabilities. This next screenshot not only discloses the technology in use, but also indicates it may be possible to execute the installation scripts, potentially resetting the site to a fresh install configuration.
Other Site Content
An organization may reveal key technologies via its web page in the form of how-to guides or Frequently Asked Question pages.
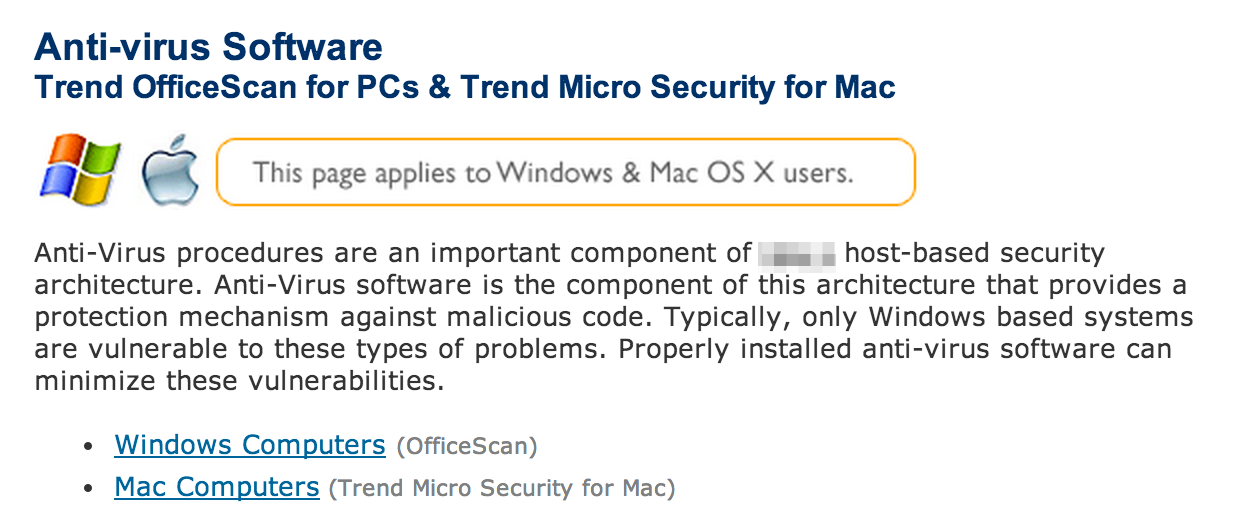
In addition to revealing technologies, organizational websites may also disclose key policies such as password creation. Be sure to take note of these findings as they may be useful for future testing activities.

Public Acquisition Records
Some organizations are required to use a publicly-advertised acquisition process and these advertisements may cite specific technologies such as this maintenance renewal for BlueCoat web proxy.

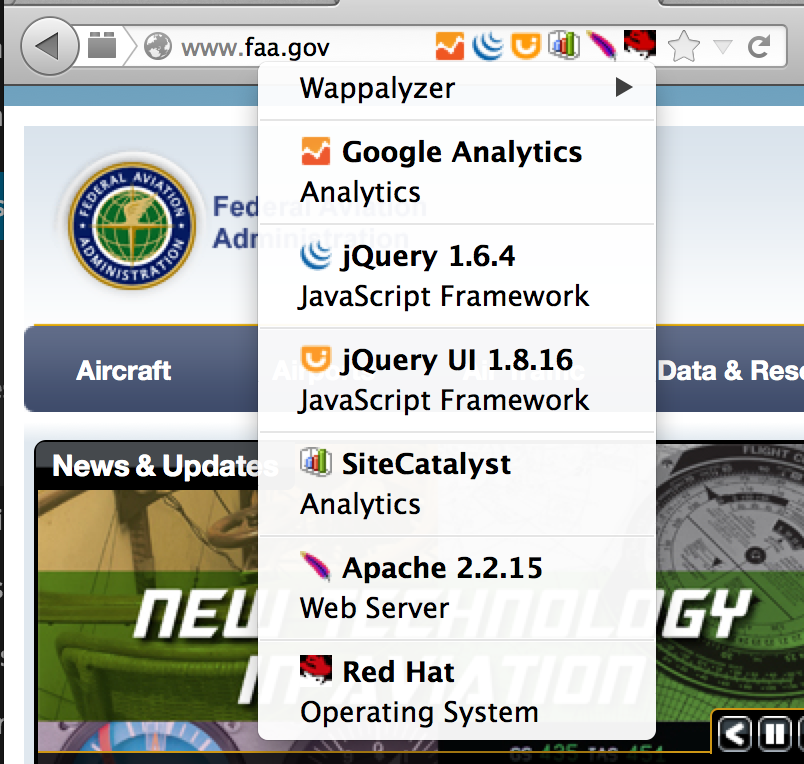
Wappalyzer
Wappalyzer is a really useful browser plugin that instantly informs you of the technologies in use on a site as you browse. Here’s a screenshot:
Using Shodan to Discover Other Public-Facing Devices
Be sure not to limit yourself to identifying only traditional web server technologies and services. Organizations often fail to properly protect internally networked devices such as printers, webcams as well as services such as SMB, leaving them publicly exposed.
Shodan is a great tool for finding these devices and publicly-exposed services.
Printers:

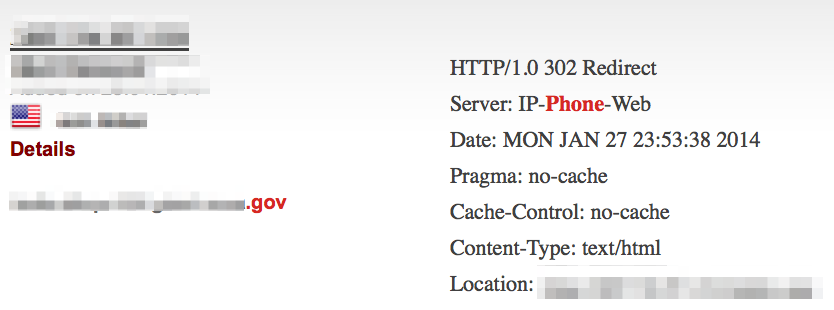
VOIP services:
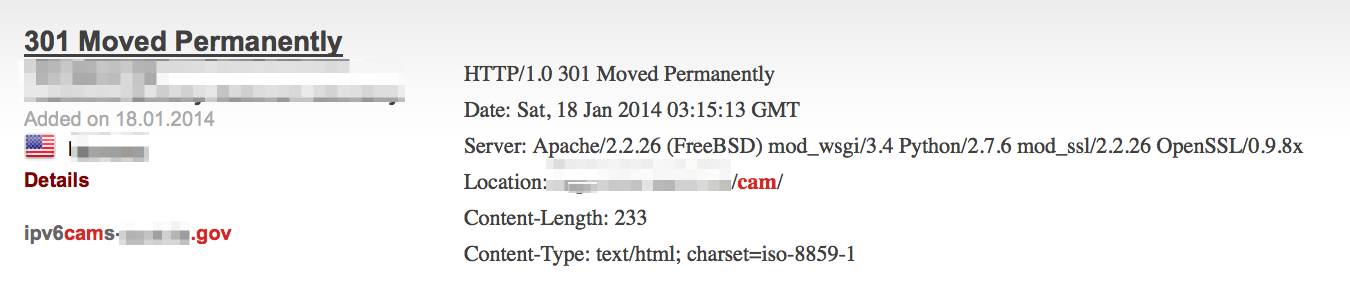
Cameras:
Shodan searches can reveal other clues about technologies in use such as virtualization technologies, mobile devices and network infrastructure:
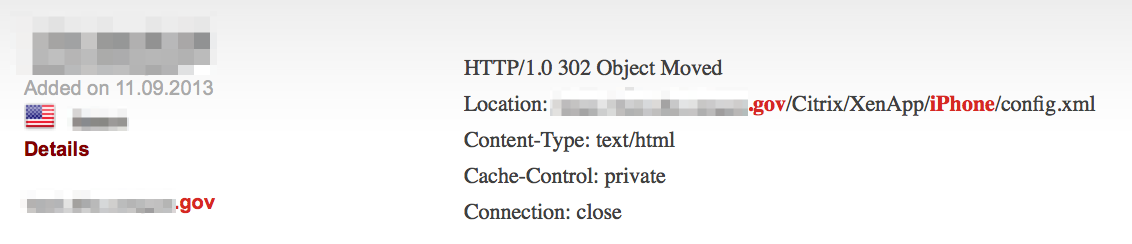
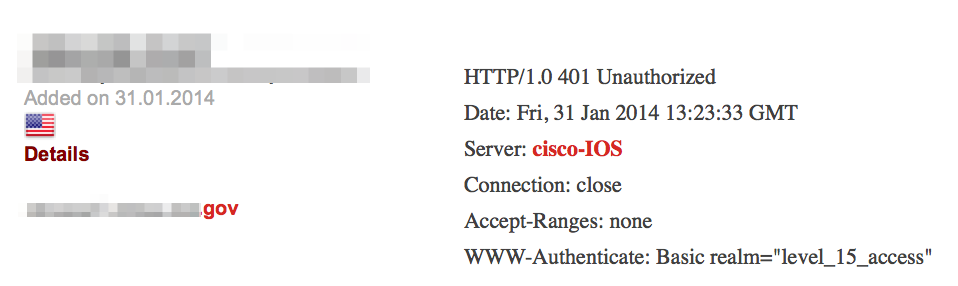
It can also help find exposed remote access services:

Failure to properly secure services such as SMB can reveal sensitive network details to the public domain.
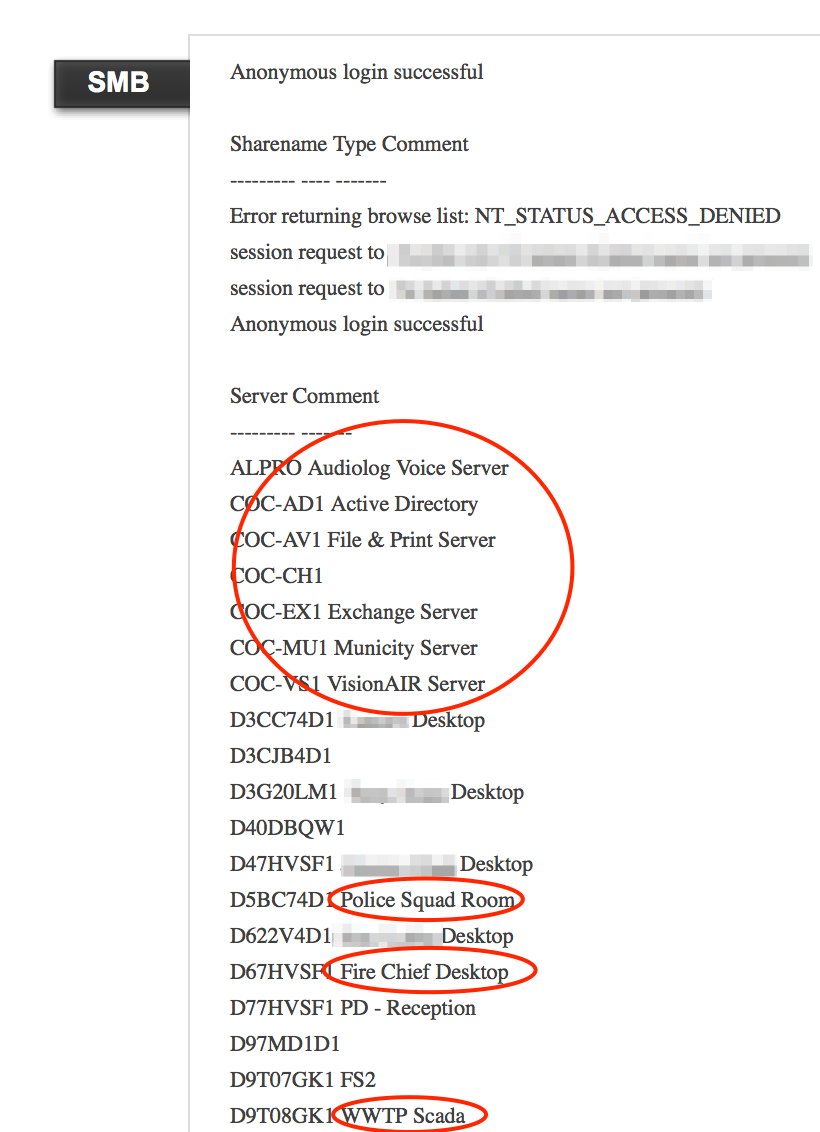
Shodan can be used to discover many more technologies and related exploits and I encourage you to check it out if you haven’t already. Google searches can be just as effective at identifying these technologies so be sure to check out the Google Hacking Database for related search strings.

Document Searches
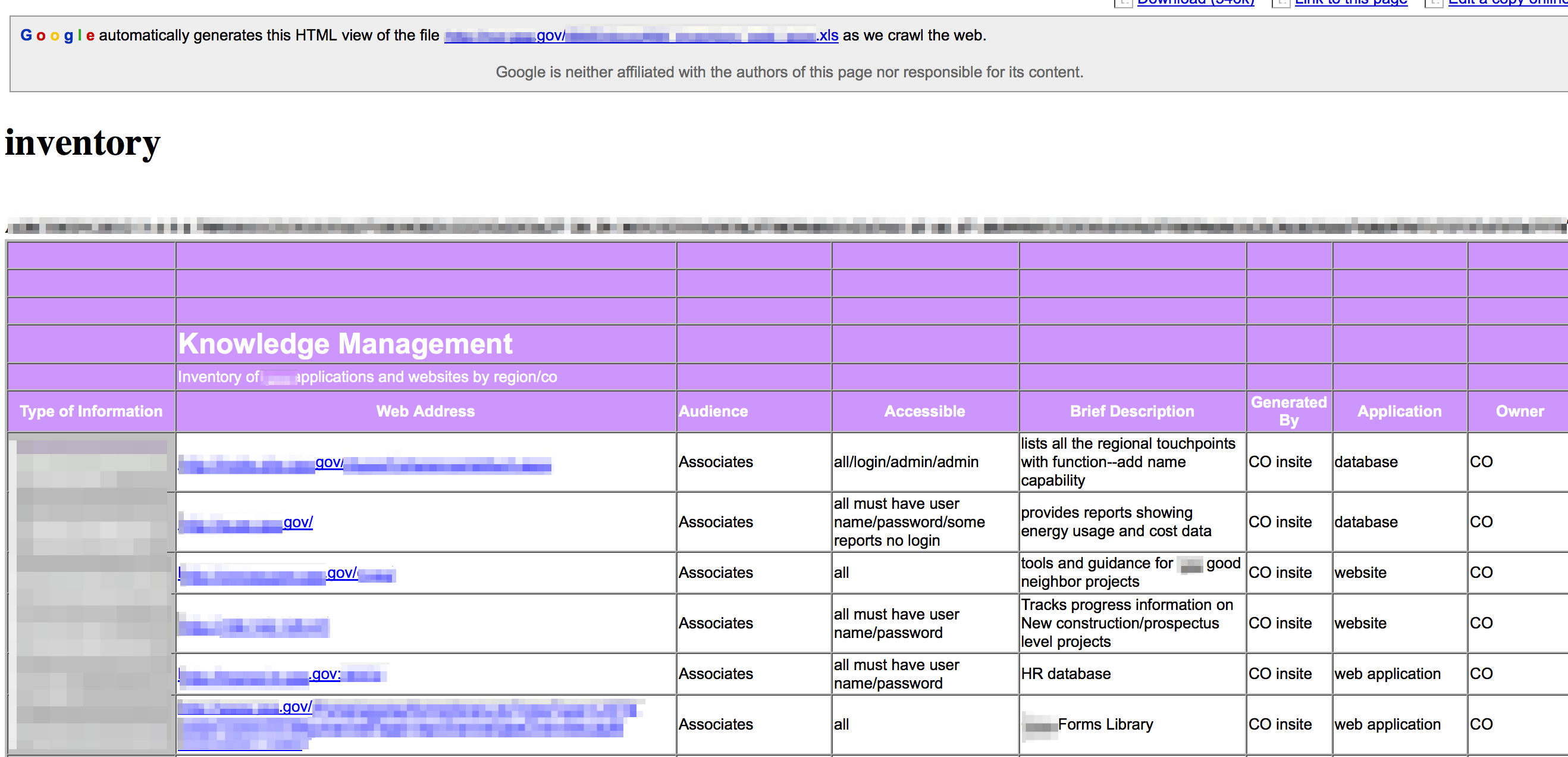
Document searches may also reveal key technologies. Consider a search such as site:<target_site> filetype:xls intitle:inventory
You may uncover an entire inventory of technologies, complete with URLs, physical locations, description, access details and more!
Identifying Content of Interest
Site content can reveal potential access points (e.g. web portals), sensitive data (login credentials), and more. As you browse the site be on the lookout for the following:
- Externally facing web portals, webmail, and administrative consoles
- Test pages
- Log files
- Backup files
- Configuration files
- Database dump files
- Client-side code
Web Portals, Webmail, and Administrative Consoles
As you navigate the site, you will want to take note of any interesting functionality that could prove useful for future penetration testing activities such as externally-facing web portals, email services, or administrative consoles. It’s possible you might come across these as you browse but you may also want to look for them with targeted Google searches.
- site: <target_site> intitle:portal employee
- site: <target_site> intitle:webmail
- site: <target_site> “outlook web access”
- site: <target_site> inurl:phpmyadmin
- etc…
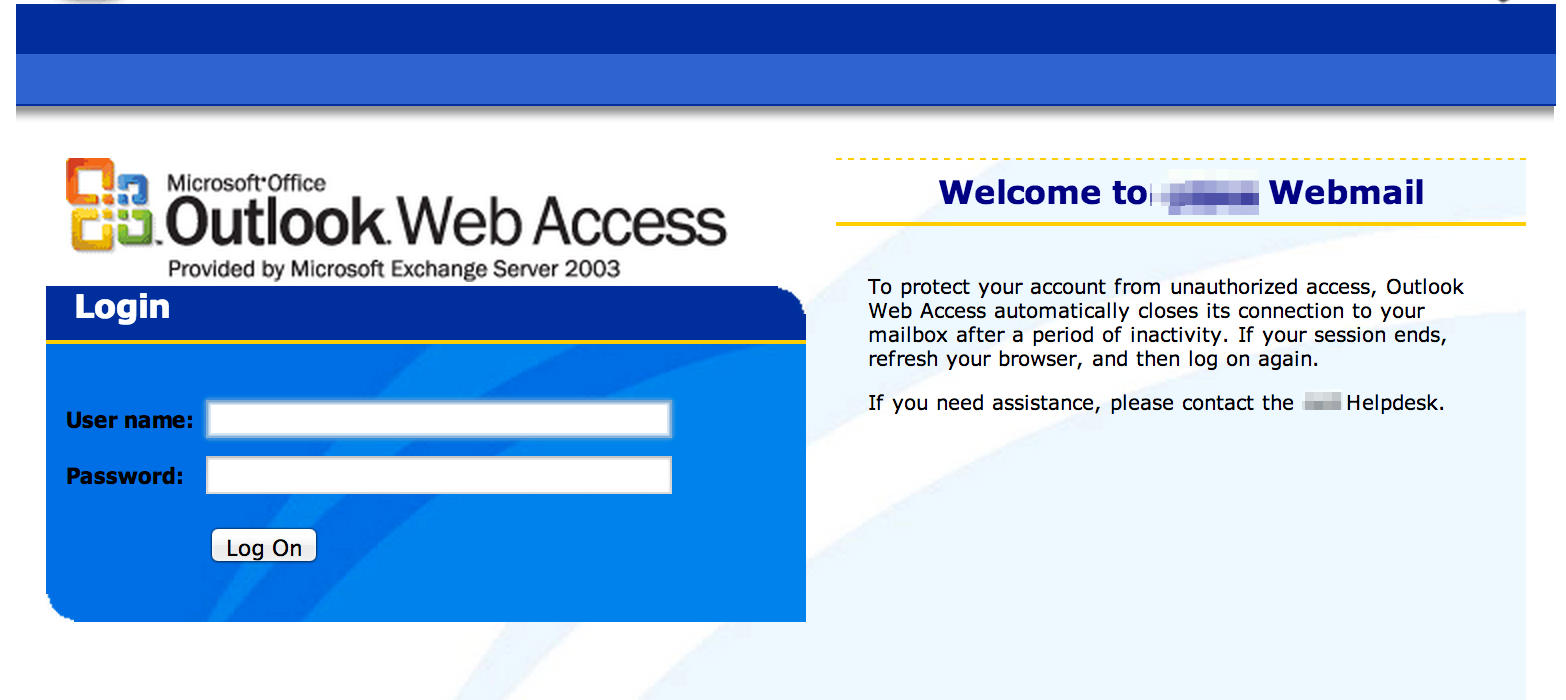
Webmail…
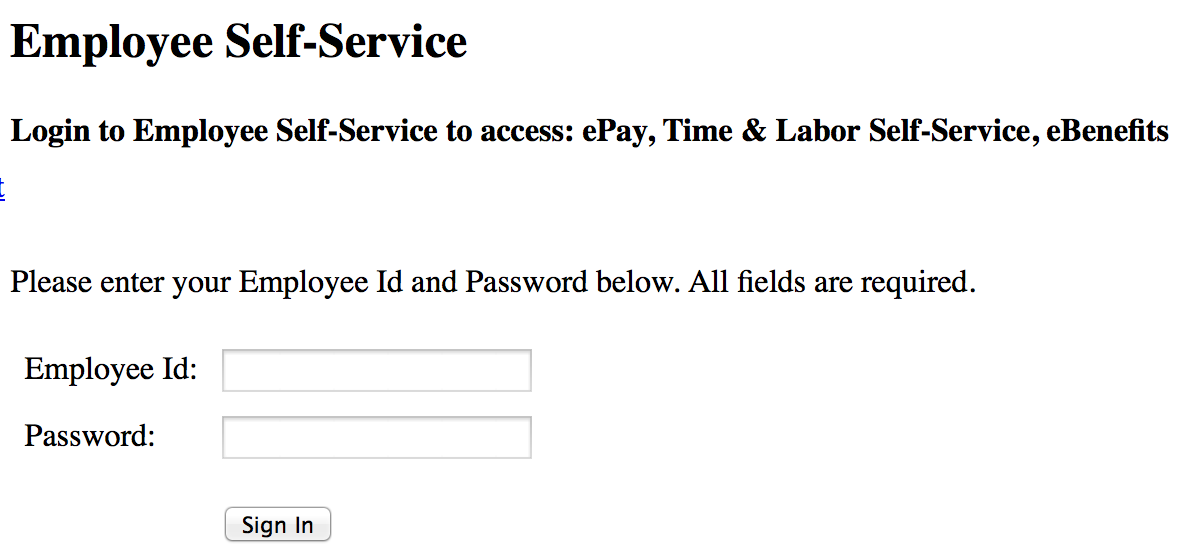
HR/Employee Benefit Portals…
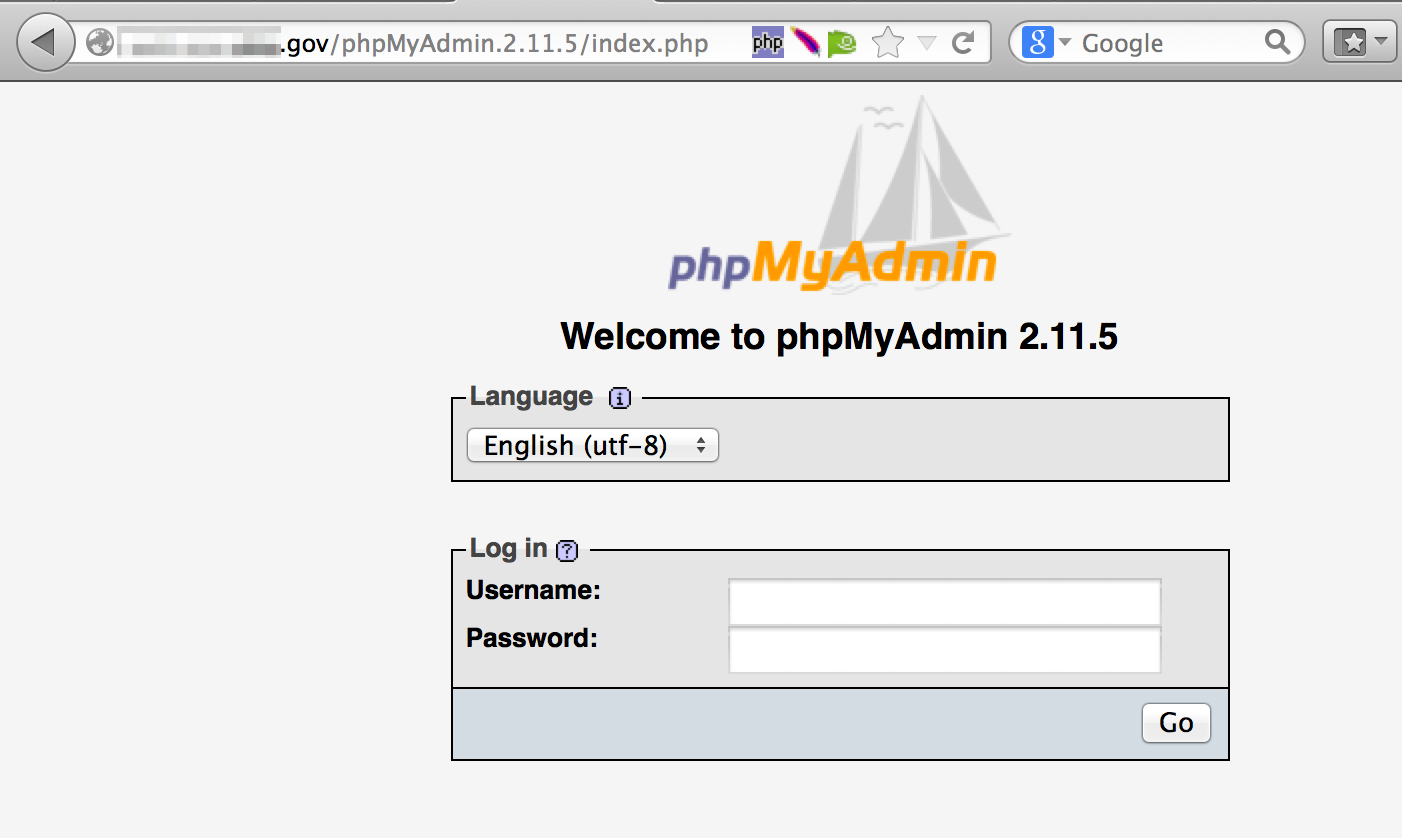
Administrator consoles…


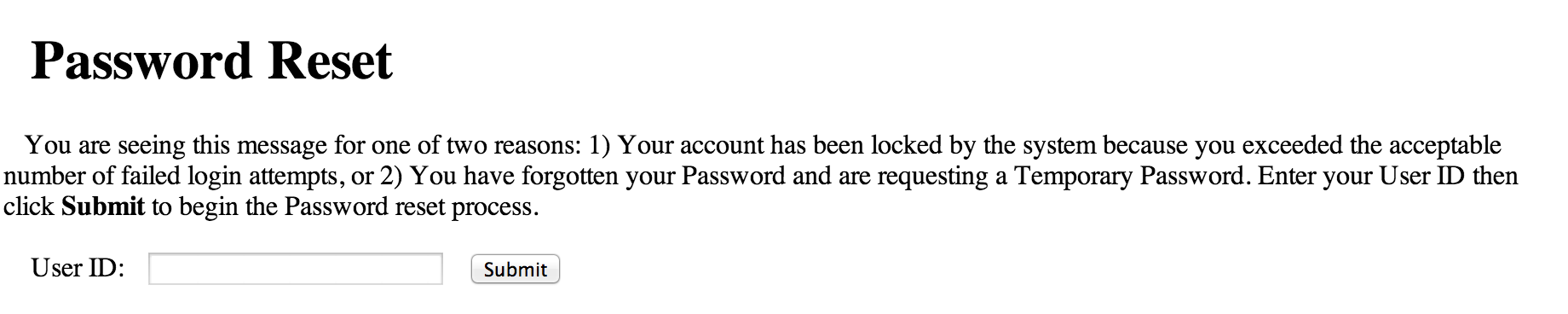
Be sure to keep a lookout for any authentication or password reset pages.
Sometimes I’m amazed at how much information about a user’s password is divulged right on the login page:
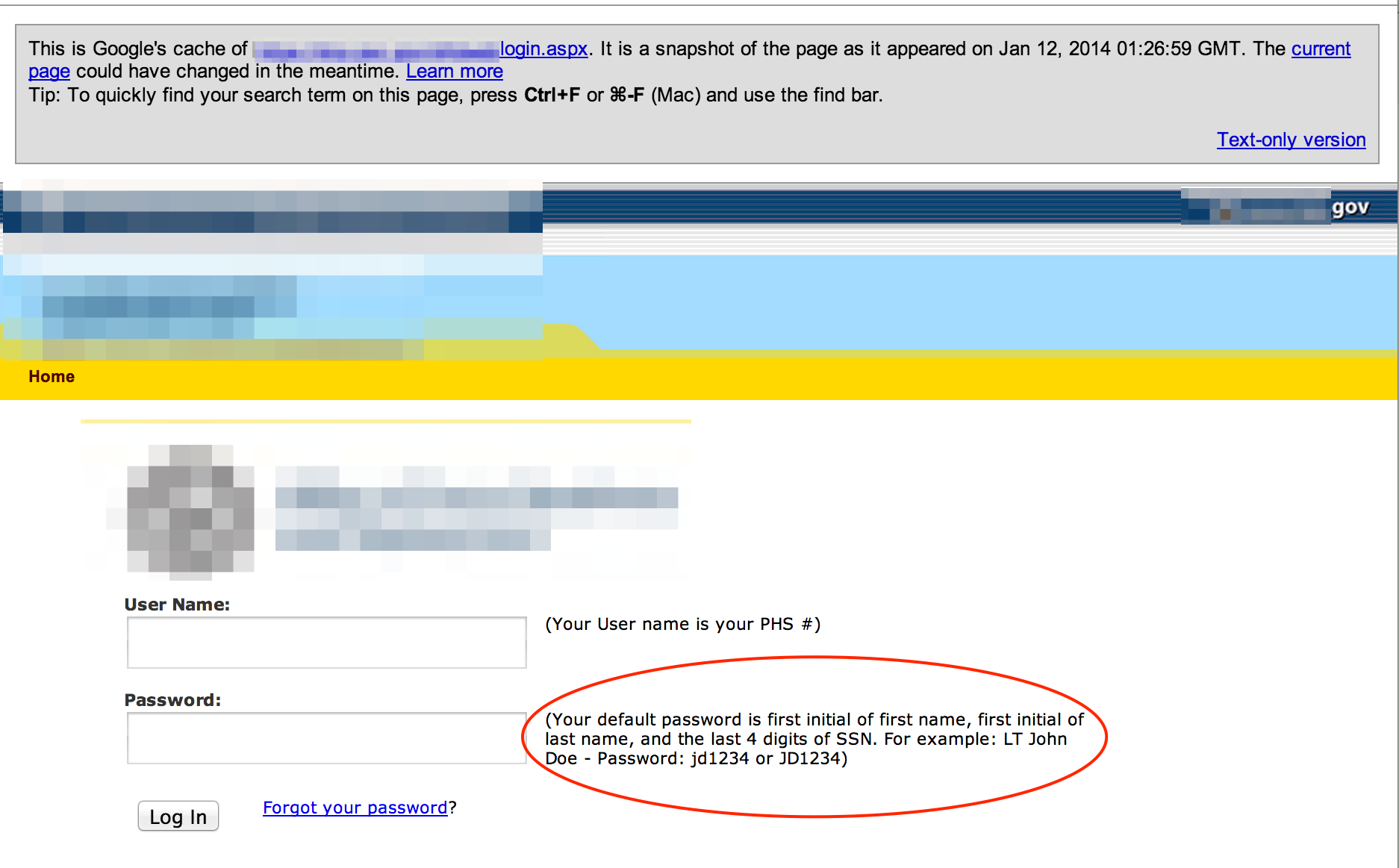
Test Pages
Be on the lookout for test infrastructure as well. Often test pages have fewer security controls or robust error messages when compared to their production counterparts, yet they frequently reside on (and provide access to) the same production infrastructure.
Log Files and Server Status Pages
Log files are sometimes left exposed and publicly accessible via Google search results. Logs can contain everything from robust errors to configuration data, IP addresses, usernames and even clear text passwords like the following debug log:

Logs files may also contain archived email or chat conversations that disclose potentially sensitive information:

Public facing web server status pages can also divulge sensitive data.

Backups, Outdated Files, and Server-side code
Sometimes web admins retain old, possibly vulnerable versions of website pages or text versions of server-side code (php, asp, etc) that can be downloaded and reviewed offline.



Another method of finding older versions of current websites is via the Wayback Machine (http://web.archive.org). For example, here’s a view of the IRS website as it appeared in 2003.
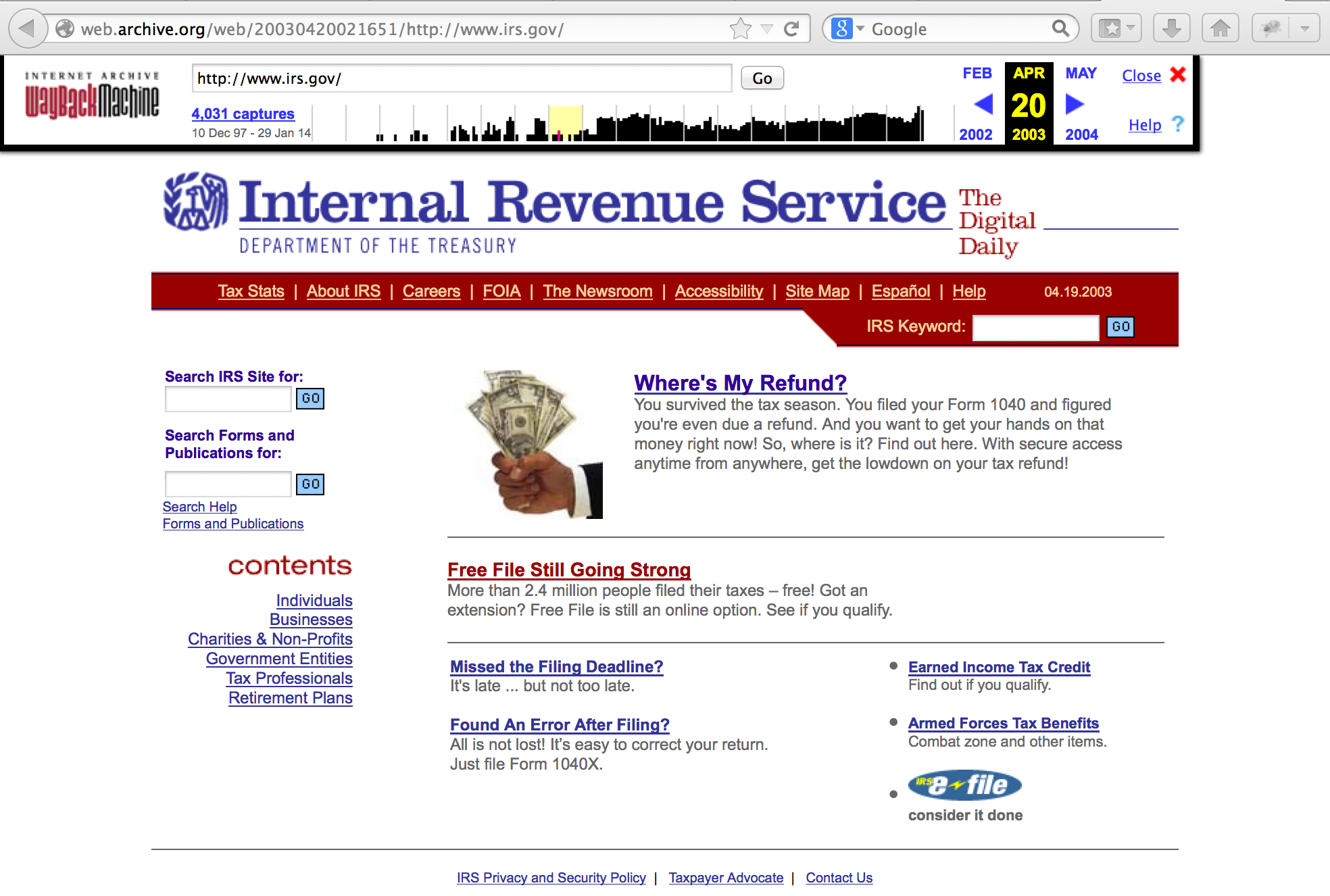
You may find now-removed references to employees, technologies, or other interesting information on these older versions of the site.
Server-side code might be found stored as as text files or accessible through indexed directories. Consider the following Google search that attempts to find php files stored as txt files.
site:<target_site> inurl:php.txt filetype:txt
You can do the same for other filetypes (.bak, .old, .zip, etc) and target extensions (.aspx, .cfm, etc).
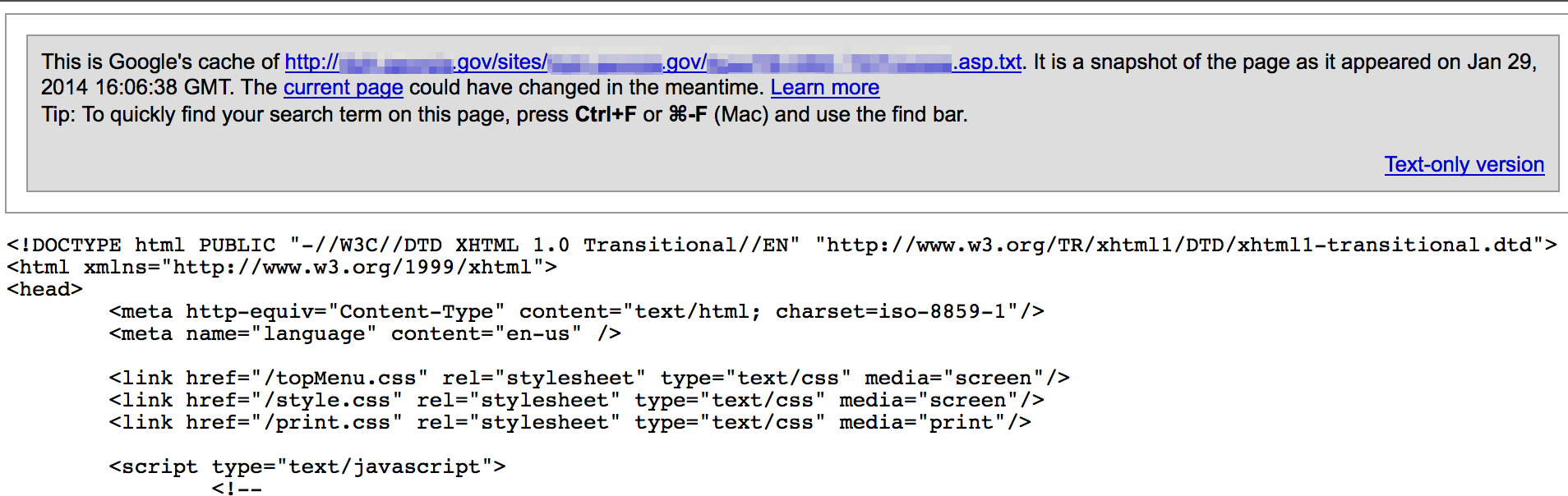
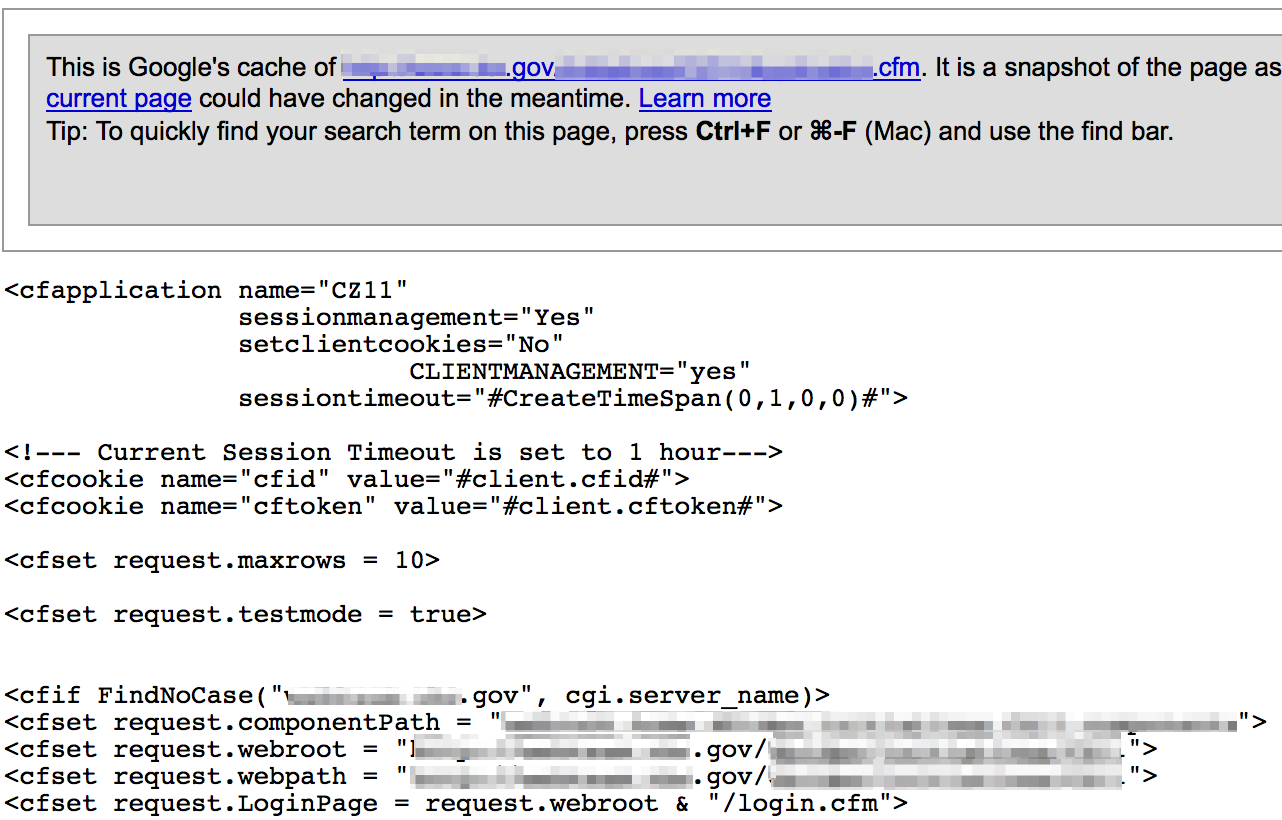
ASP .asa files can be a source for usernames, passwords, and other config data.
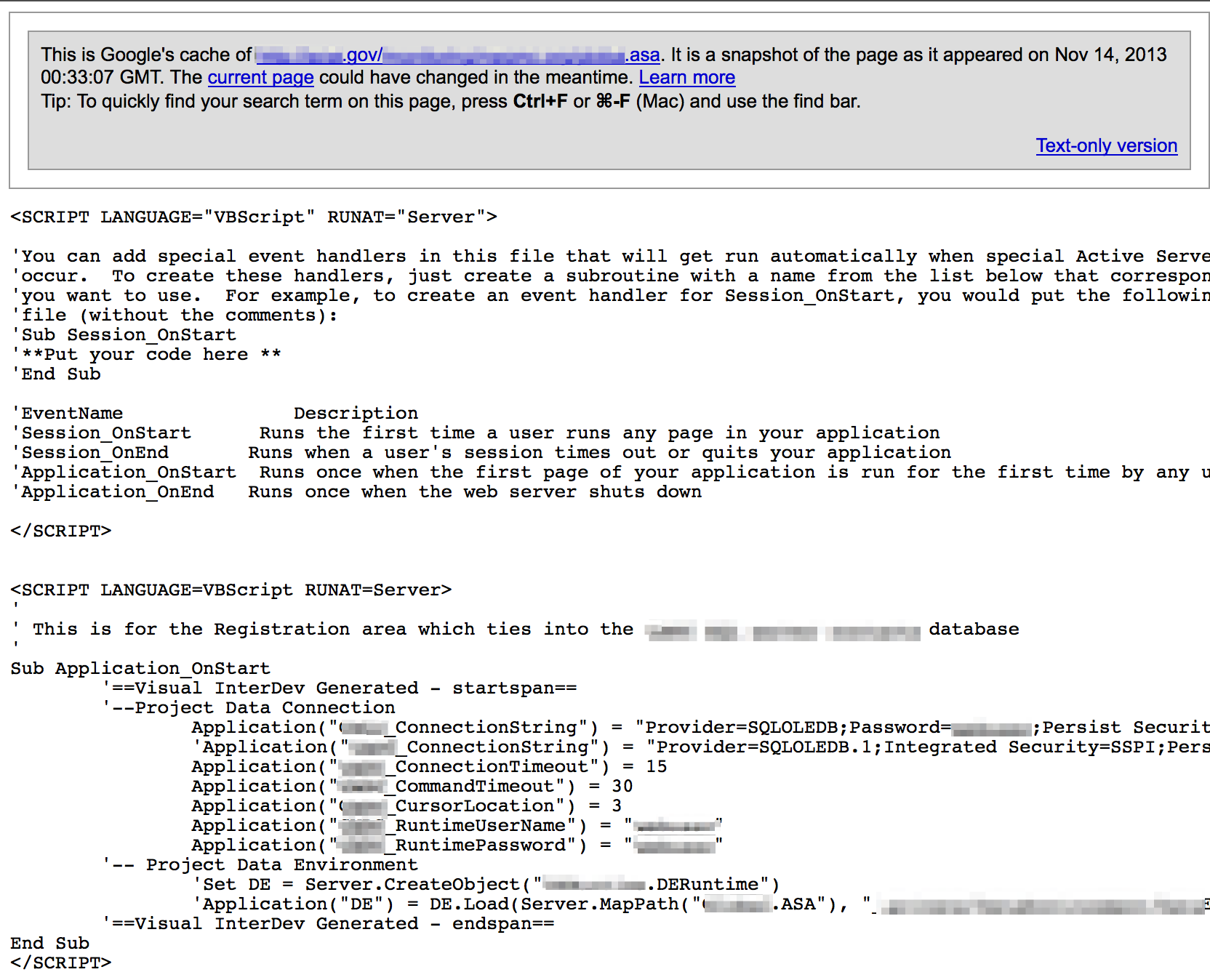
Configuration files
Configuration files can contain sensitive connection strings, passwords, IP addresses and other valuable information.
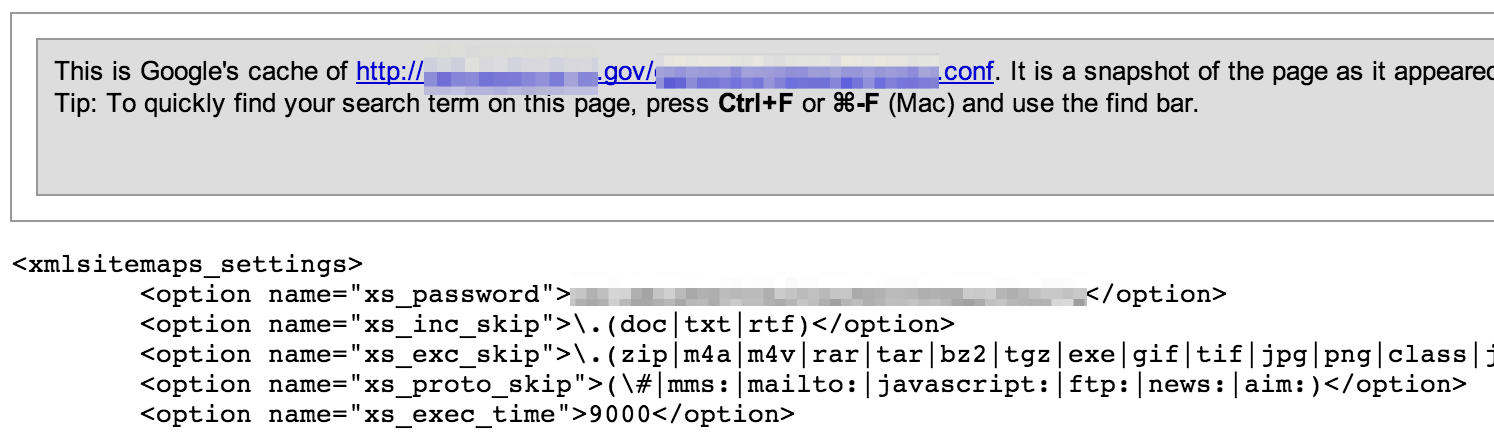
Be sure to look for multiple variations of file extensions including .config, .conf, .cfg, .ini, etc.
Database Dump Files
Similar to configuration files, database dump files can contain sensitive information such as table structures and queries (for use in SQL injection testing), names, email addresses, usernames, and passwords. Searching for filetypes of sql, dbf, mdf, dat, or mdb (among others) can uncover these files.
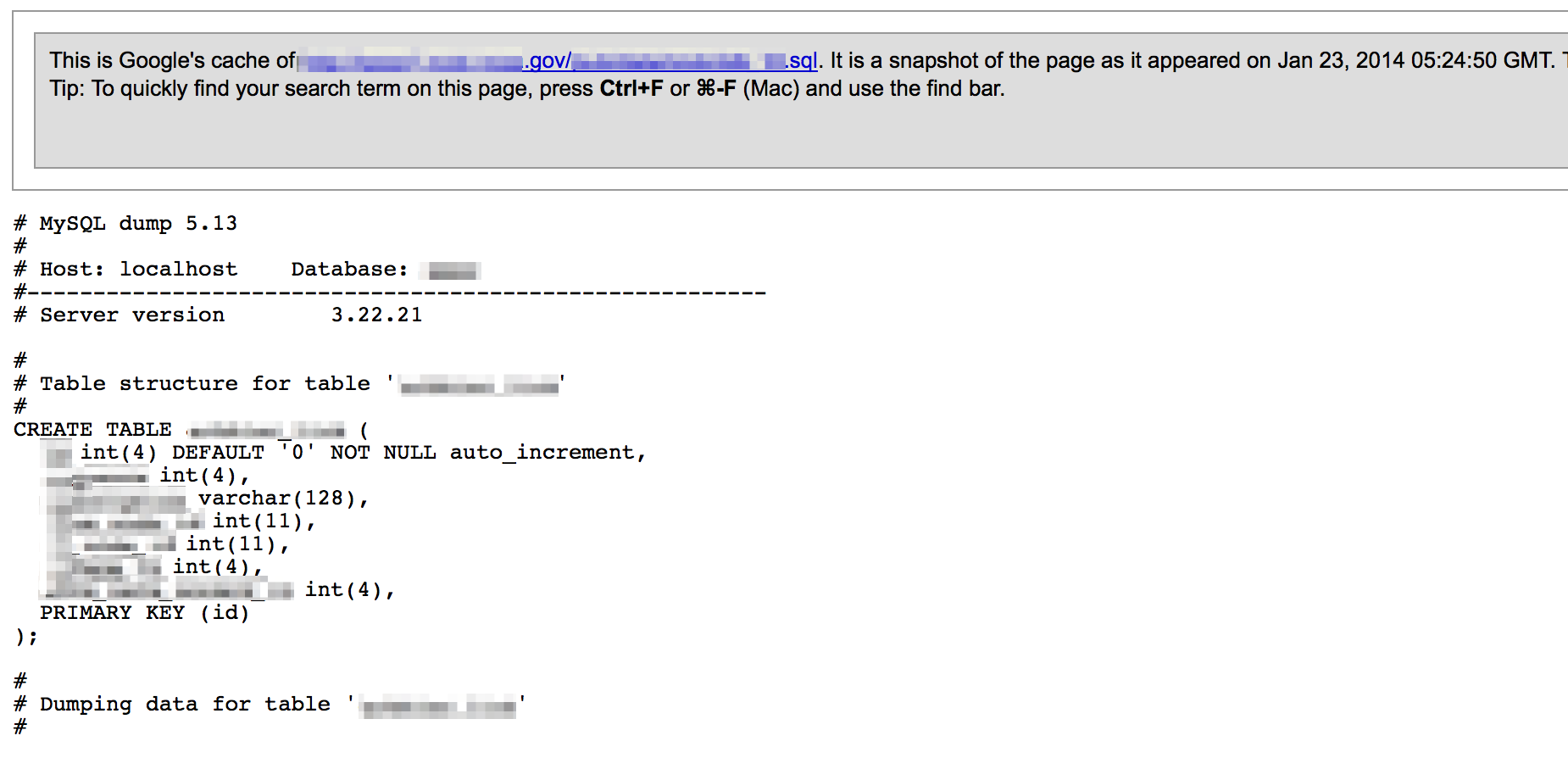
Sometimes third-party sites such as Pastebin can turn up the same information…useful if the site has since been fixed and the content removed from Google cache.
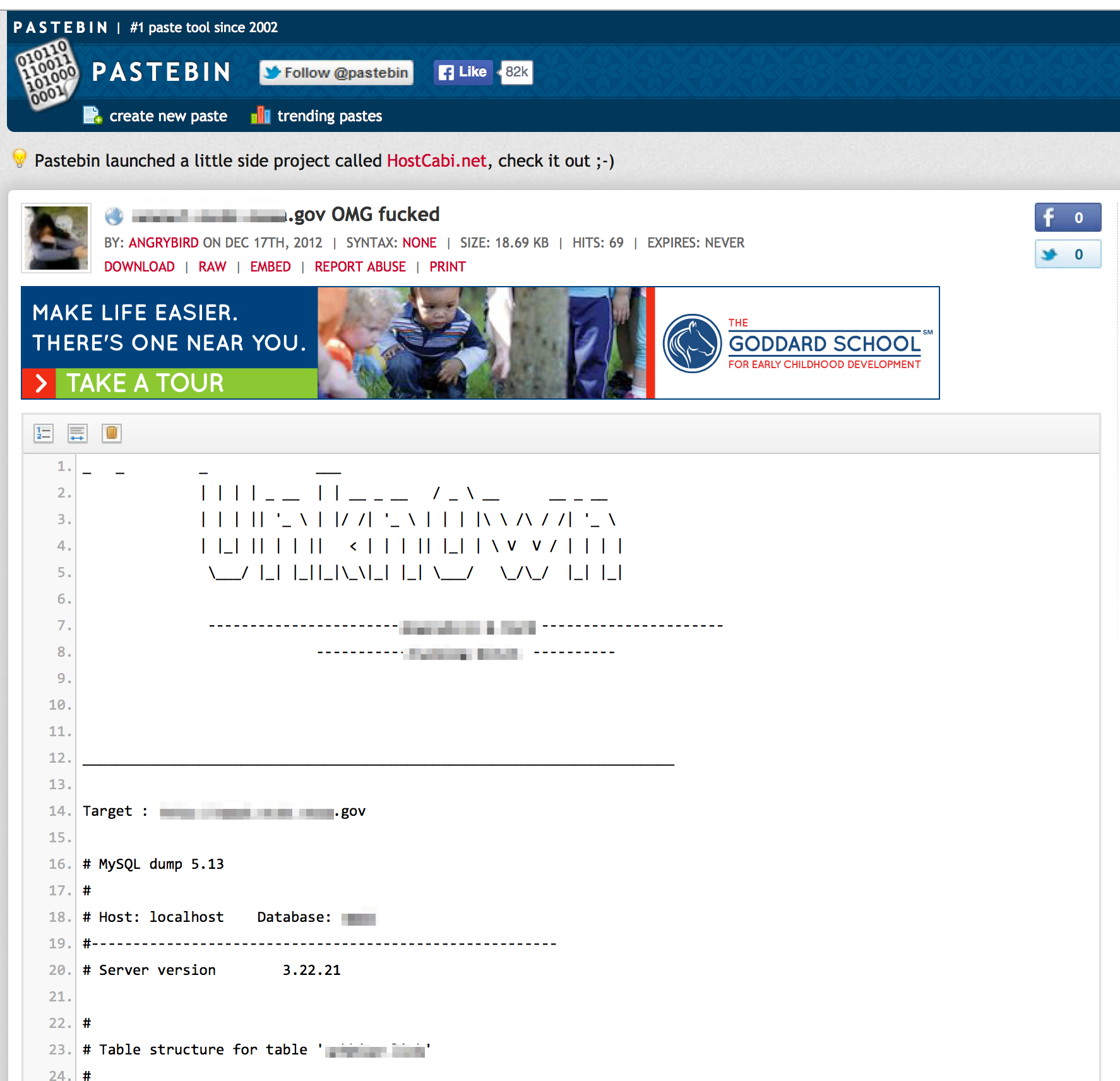
If you know the content was once posted to the public domain but can’t locate it via Google cache or sites like Pastebin, don’t forget about archive.org’s Wayback Machine.
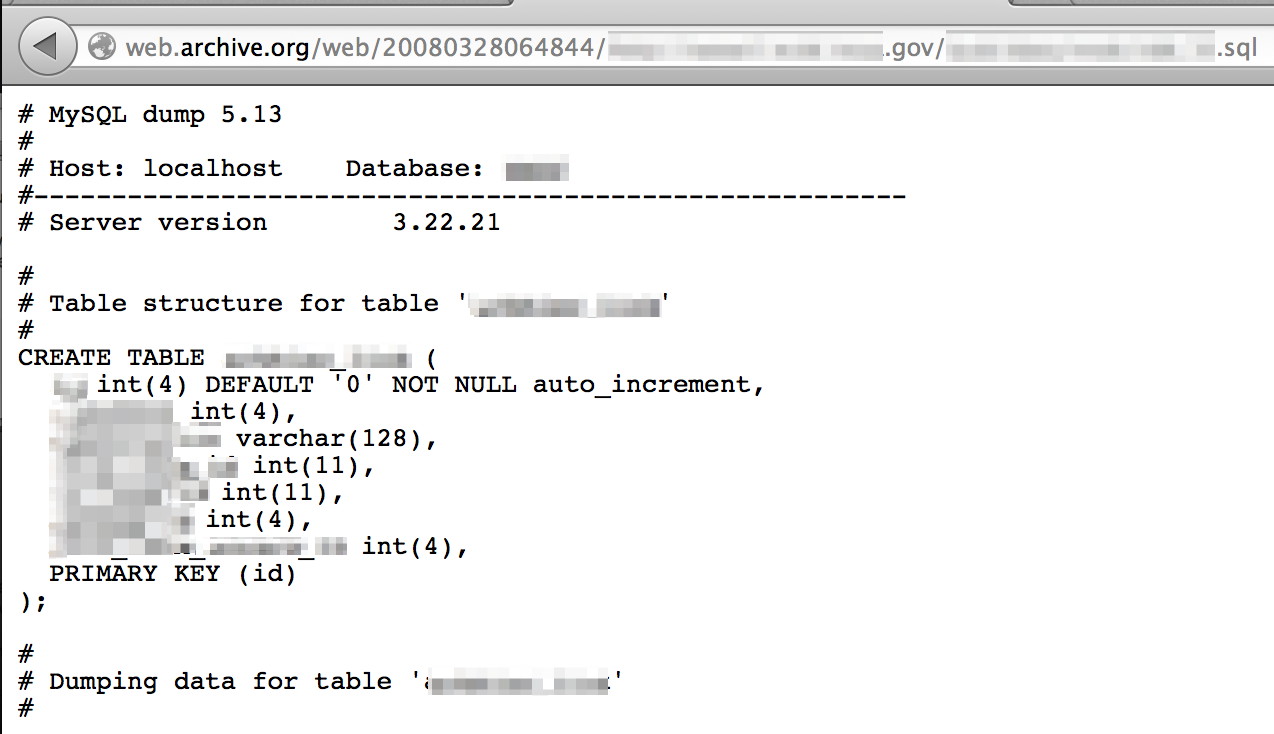
Database files can be a good source of identifying organizational users as well as valid passwords:

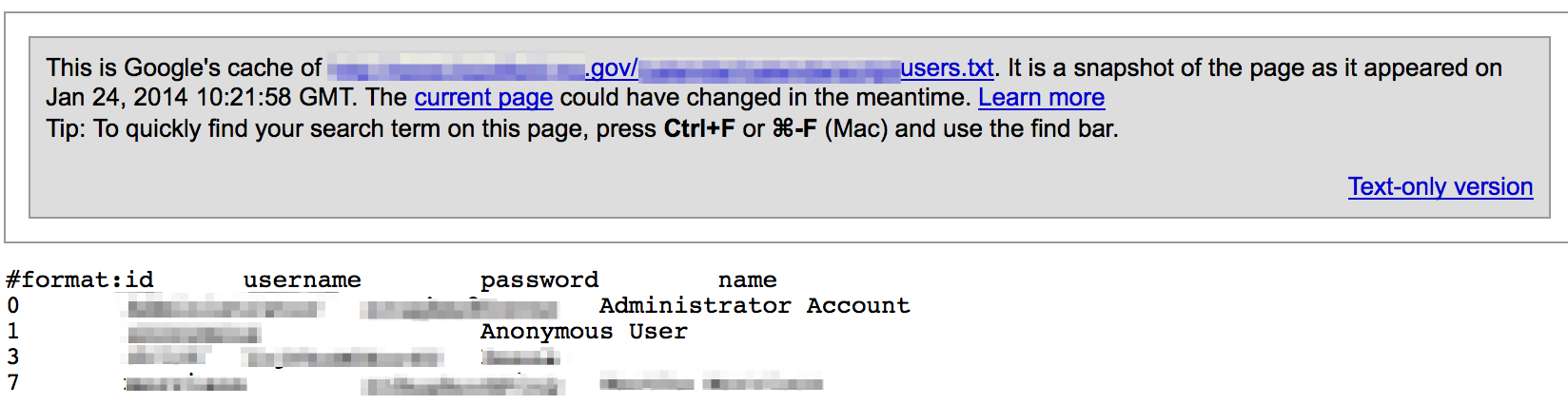
User and Password Files
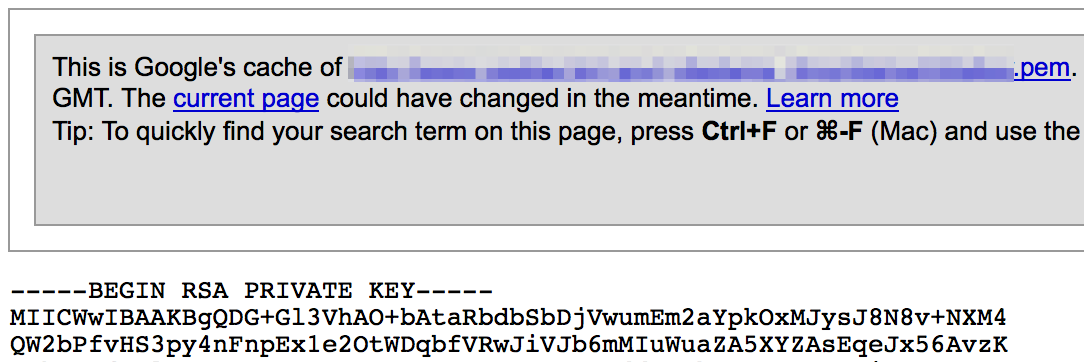
For whatever reason, some sites are found to be publicly hosting files containing usernames and passwords.

In addition to plaintext or hashed passwords, you may also find pem files containing private keys:
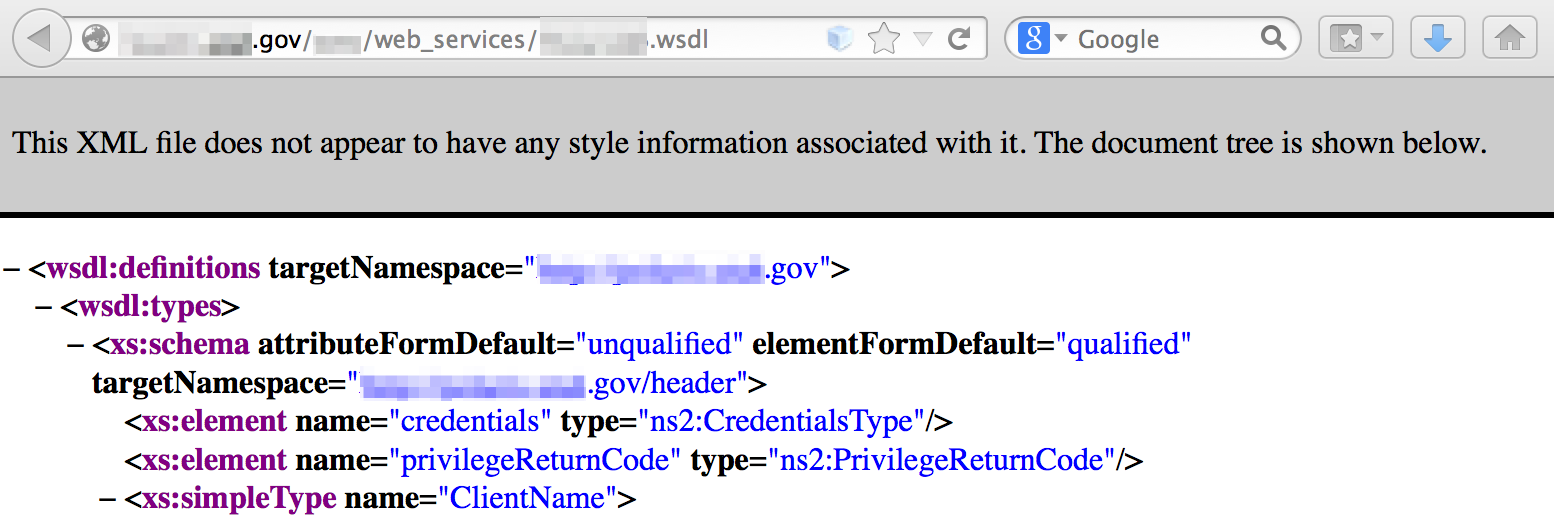
Web Service Definition Language files
If you plan to assess a site’s web services for potential vulnerabilities, locating the wsdl can be a valuable resource for identifying function names and associated parameters.
Client-side Code
Review of client-side HTML and scripts can reveal sensitive data or even vulnerabilities such as unsafe handling of user-provided data. BurpSuite Pro has an engagement tool called “Find Scripts” which will search the specified hosts(s) in your site map and extract content for review.
Here’s an example output:

Client-side code can reveal robust error messages that may assist you in enumeration attacks in later phases of your pen test.

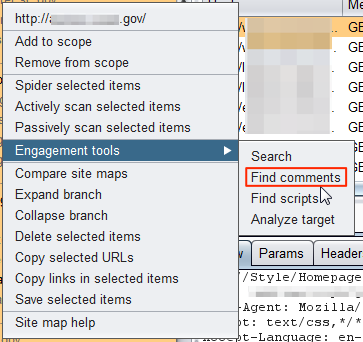
HTML comments can be a source of useful information. It may be rarer these days to discover clear-text credentials, but other information such as software version information, contact info, IP addresses or other configuration data can still be found. BurpSuite Pro has a nice engagement tool called “Find Comments” which will look through the specified site(s) in your site map and extract comments for review.
Alternatively, you can use the previously mentioned Burp Pro Search feature to search all of the client slide code of sites you’ve visited. Be sure to extend your offline code reviews to CSS, SWF and other available file types.
Search engines can also help identify interesting code. For example, nerdydata.com allows you to search a site’s html source.
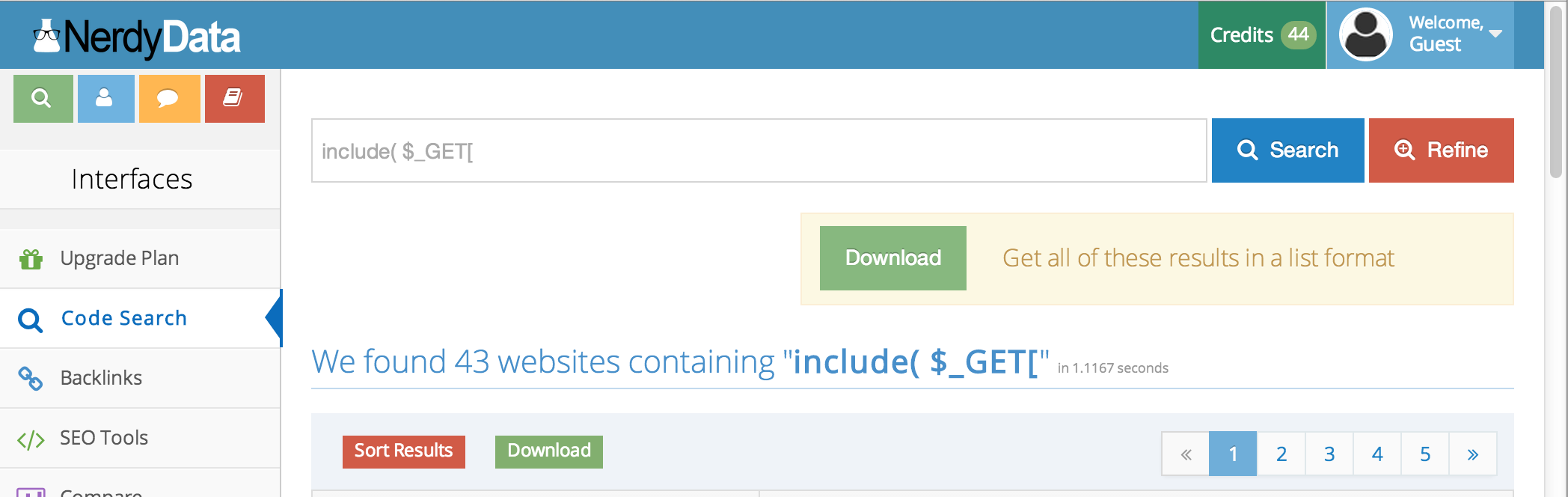
The number of searches and the corresponding results are limited for non-subscribing users. If you think it’s something you might use regularly, individual and enterprise-class subscription plans are available.
Other Documents of Interest
I’ve already covered how document metadata can be used to obtain data about an organization’s personnel and internal network structure as well as sensitive content such as passwords or SSNs. These documents can also contain proprietary information, intellectual property, specifics about vulnerabilities, results of past security testing, etc. Keyword searches for terms such as “not for distribution” or “confidential” might uncover sensitive documents posted to the public domain. Of course there’s always the possibility that what you find has since been declassified/approved for public consumption…but maybe not.
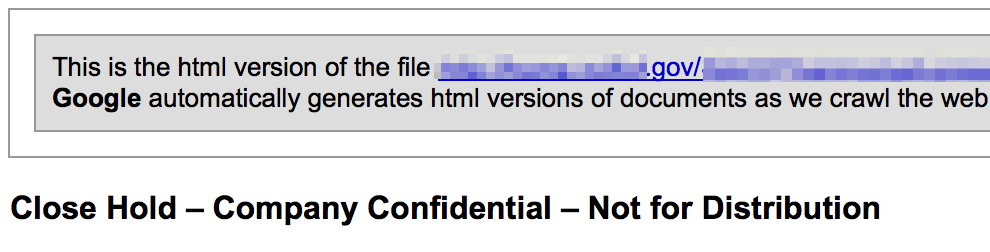
Cloud-based data repositories such as Google Drive and Dropbox may also host publicly-accessible files of interest including policies, meeting minutes, archives, or other office documents of interest.
site:drive.google.com -intext:”google drive” <search_terms>
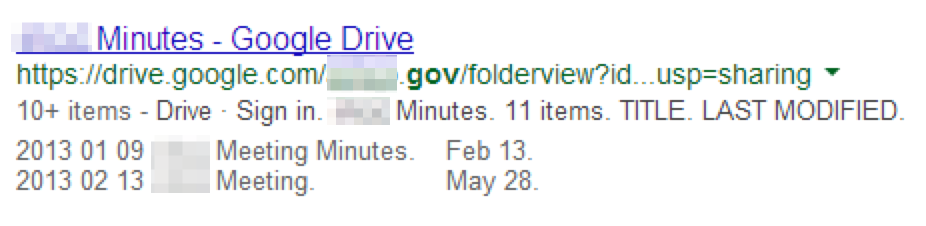
Identifying Vulnerabilities
Now that you’ve gathered as much information about the site, including the technologies it employs and other content of interest, it’s time to use passive reconnaissance techniques to identify potential vulnerabilities. While it’s true that in most cases these passive techniques cannot definitively guarantee a vulnerability is exploitable, they are good indicators and can help scope your efforts once you move to (sanctioned) active penetration testing activities.
The following are some of the methods you might use to identify vulnerabilities:
- Researching known software vulnerabilities based on identified technologies
- Examining URLs
- Passive scanning via an intercepting proxy
- Reviewing error messages
Much of what I’ll demo is accomplished via Google searching and I’m only going to scratch the surface of the possible vulnerabilities you might uncover. One of the best resources you can turn to for passive Google-based vulnerability discovery is the Google Hacking Database maintained by Offensive Security.
Researching Known Software Vulnerabilities
With the knowledge of system and application versions in use, you can reference sites like http://www.cvedetails.com or http://www.exploit-db.com to see if there are any known vulnerabilities or available exploits that might be useful in follow-on penetration testing activities.
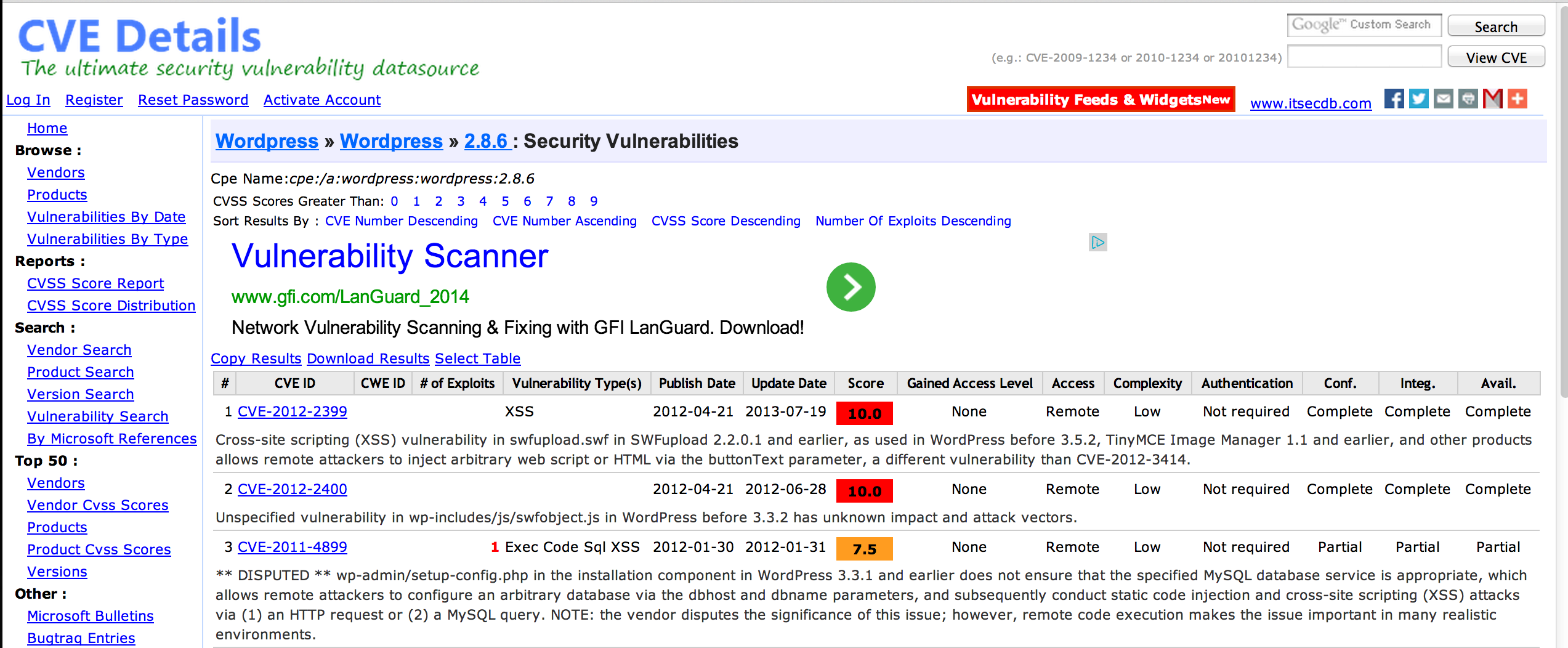
For example, by knowing the type of CMS employed (e.g. WordPress) you can see if there are any plugins or modules with known vulnerabilities and then check for the presence of those modules using passive recon.
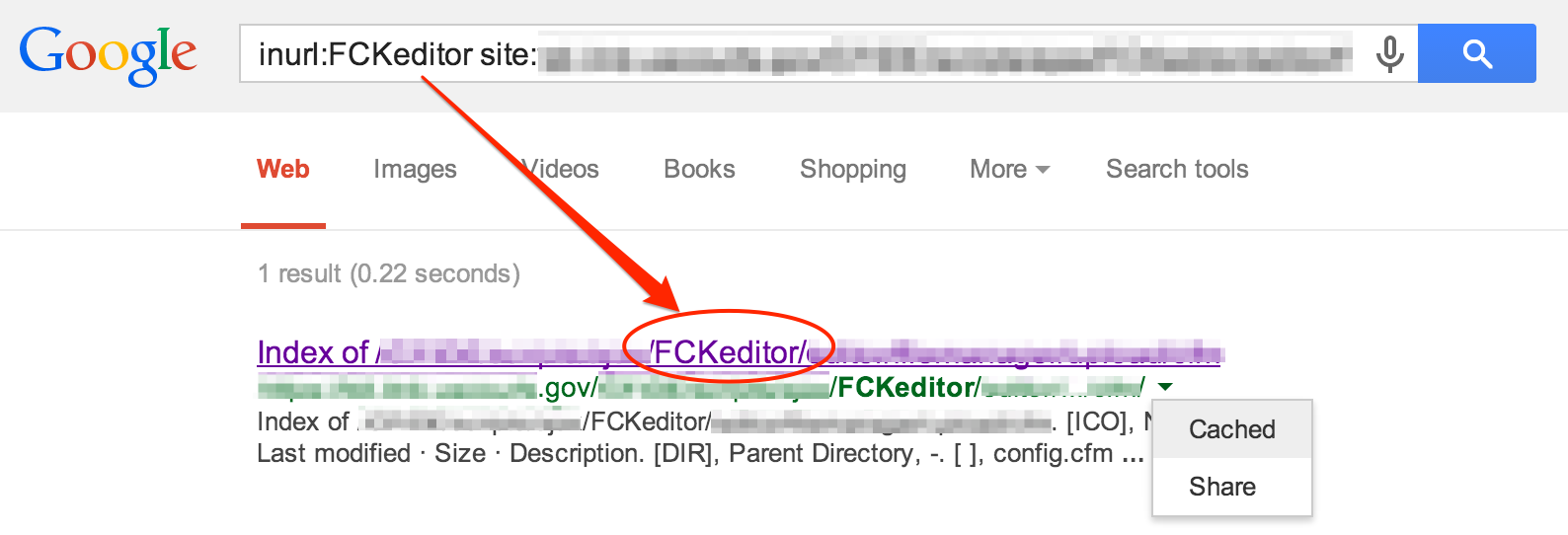
The Google Hacking Database also has a collection of Google hacks designed to locate specific vulnerabilities based on published advisories.
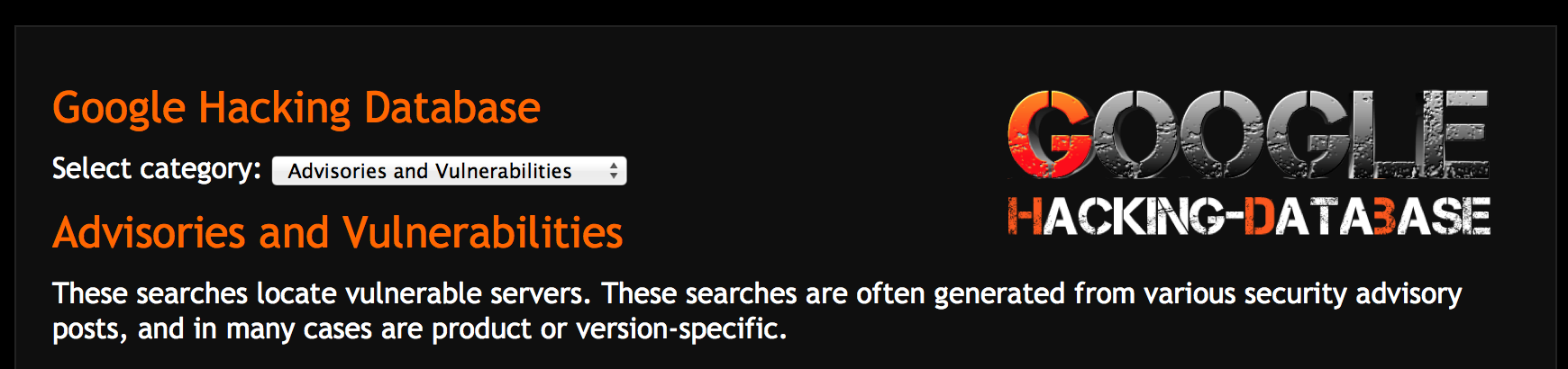
Tip: if you’ve got a target site in mind and you want to use the search string links directly from GHDB, you can configure your intercepting proxy to automatically modify the URL and append your designated “site:” parameter.


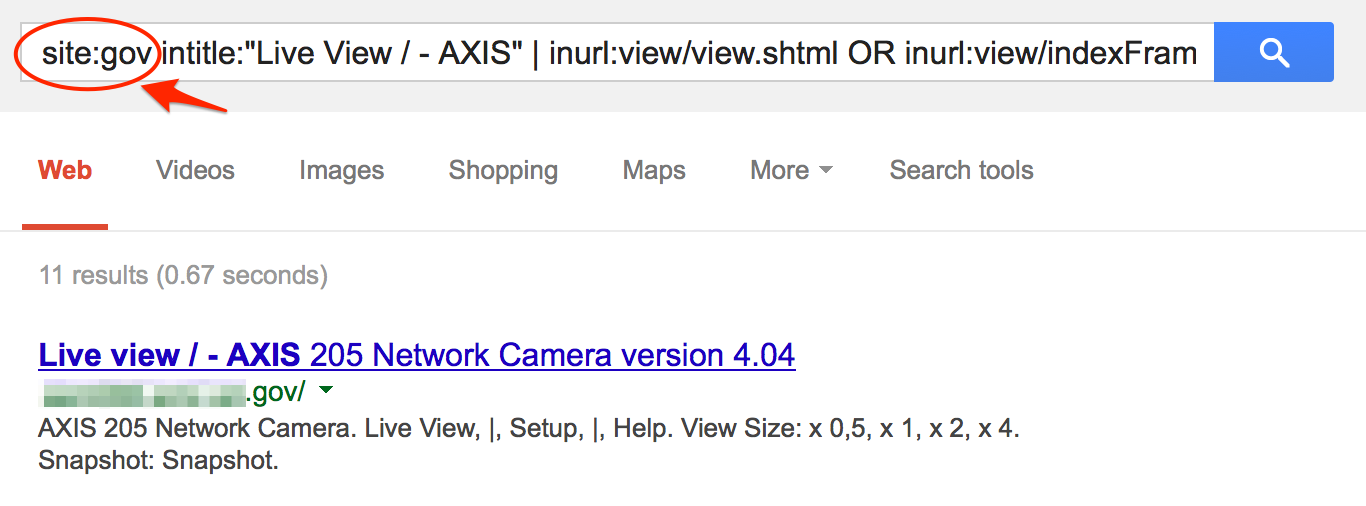
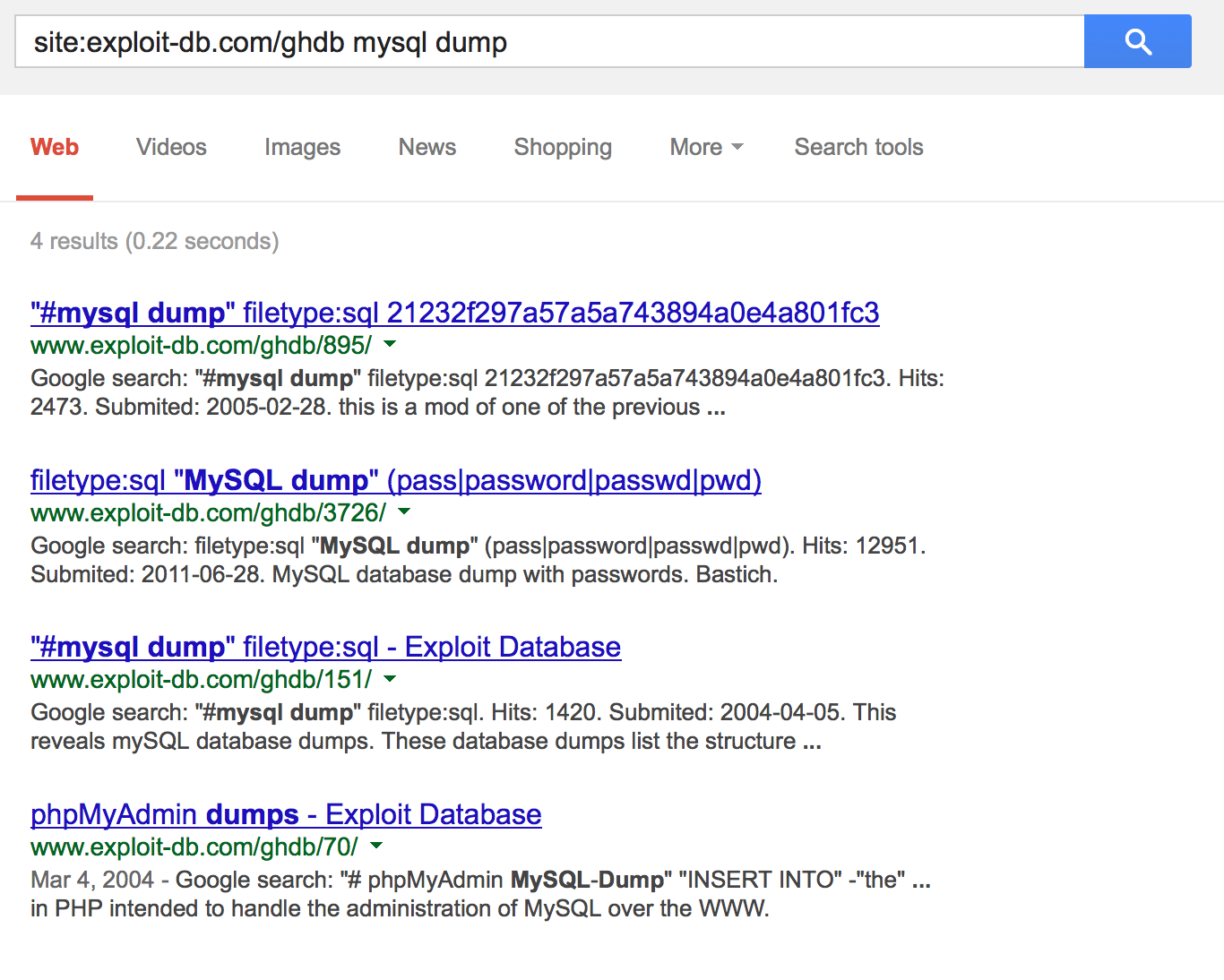
As an alternative to browsing the GHDB directly, you can also use Google to quickly find a hack related to a specific technology or vulnerability: site:exploit-db.com/ghdb <search_term>
Examining Search Results and URLs
URLs returned in search results can be great indicators of the presence of potential vulnerabilities such as unvalidated redirects or file inclusion vulnerabilities.

![]()
Here’s an example of a potentially insecure relative path reference to an swf config file.
![]()
Note: Be sure to also download and inspect the swf file as well!
URLs might indicate a site has exposed an insecure function or even worse, has already been compromised.
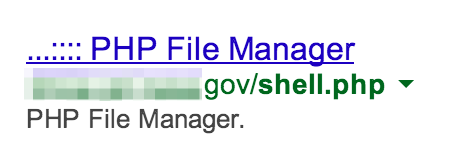
They can also directly disclose sensitive data such as usernames and passwords (and reveal insecure practices such as passing login credentials via GET parameters):
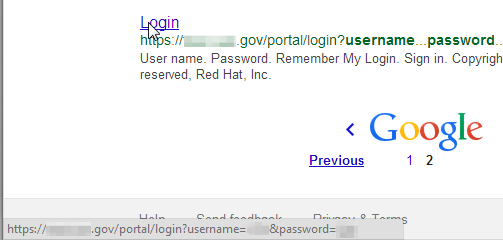
Locating any of the above potential vulnerabilities can be accomplished via the inurl Google search parameter. For example: site:<target_site> inurl:shell.php filetype:php
Google search results can sometimes uncover XSS vulnerabilities. Pay attention to results returned for a site’s search function. Queries such as the following might help you identify a search function on your target site:
- site:<target_site> inurl:search
- site:<target_site> inurl:search inurl:q=
You may see clues in the search results that a site is not properly encoding output. The inclusion of doubled-up quotes in the title or URL can be a giveaway. For example if you see a search result title such as Results for “”<search_term>”” or a URL such as http://target.site.com/search.aspx?query=%22%22<search_term>%22%22, check the source of the Google cache result to see if they have been properly escaped or encoded throughout the response. Pay attention to tags, returned messages, and input values. Obviously this is something that is easily tested by submitting a quoted search term to the site, but that goes beyond the scope of passive reconnaissance.
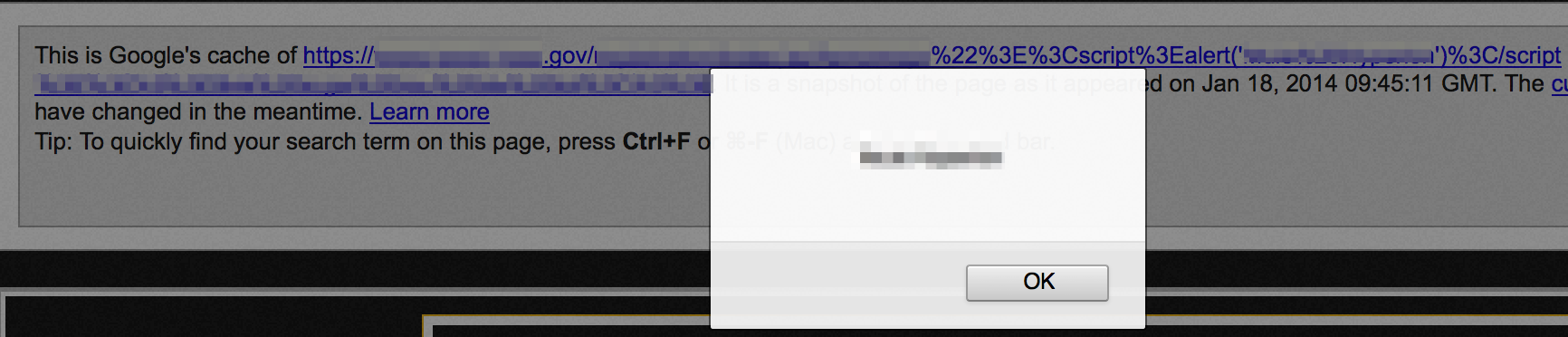
There may even be times when you notice confirmation of a reflected XSS vulnerability that has been cached by Google, such as the following example:

Since the reflected XSS injection string is stored in Google’s cache, it will execute when viewed and you’ve pretty much verified this site’s vulnerability.
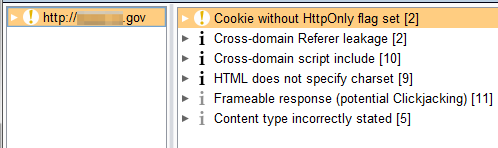
Passive scanning
BurpSuite Pro has a vulnerability scanner function that can be put into passive mode. It’s helpful at quickly identifying issues (such as missing cookie flags, cross-domain issues, etc) without having to manually examine server response contents or perform active scans against the site.
Error Messages
Error messages are possibly one of the most valuable indicators of the presence of vulnerabilities and lend themselves quite nicely to passive reconnaissance. You can use some generalized Google searches to uncover errors if you’re not quite sure what you’re looking for:
- site:”<target_site>” “unexpected error”
- site:”<target_site>” “encountered an error”
- site:”<target_site>” “experienced an error”
- site:”<target_site>” inurl:error
- site:”<target_site>” inurl:err_msg
- etc.
Sometimes errors won’t divulge a specific vulnerability but will return stack traces, function names, or other information that can be helpful in identifying the server-side code or underlying technologies.
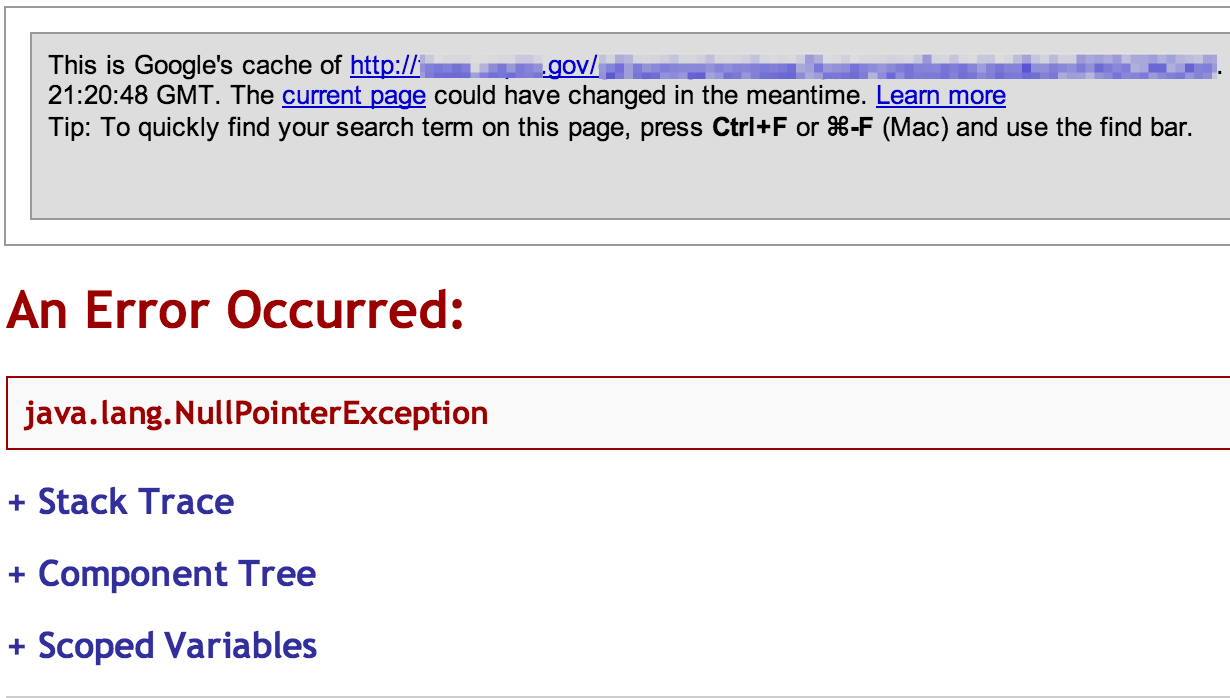
When looking for error messages that might divulge vulnerabilities, try to leverage the information you’ve already collected and limit your scope to technologies you know are in use. For example, if you know the site is running coldfusion, search for CF-specific errors:
site:<target_site> “error occurred while processing request” “coldfusion”
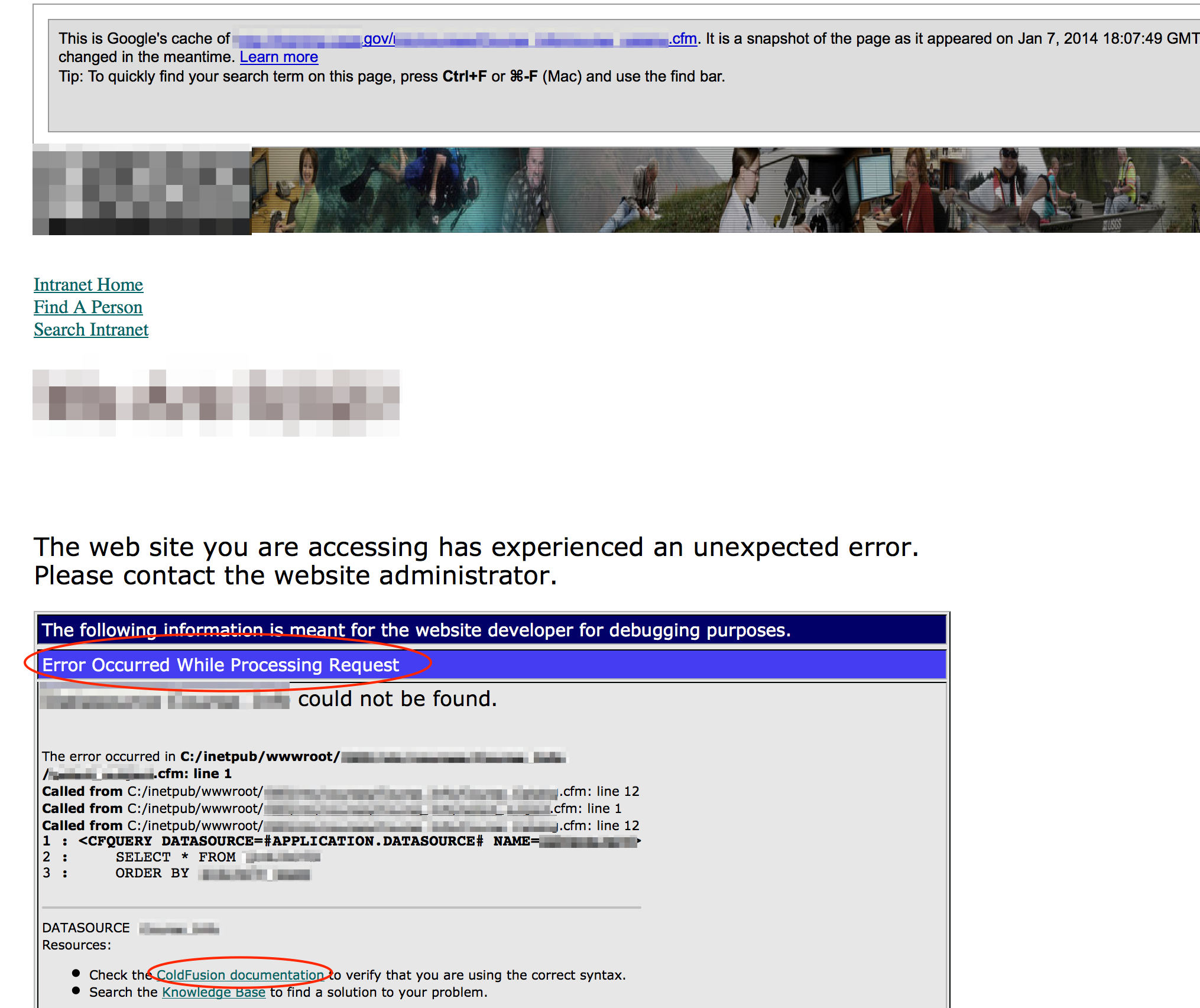
Sometimes the errors themselves can reveal the underlying technology. Take the following error for example, that reveals the use of XAMPP on a Windows machine.

Be on the lookout for errors that might indicate file inclusion vulnerabilities which can lead to local data disclosure or remote code execution (further testing will be required for exploit verification).
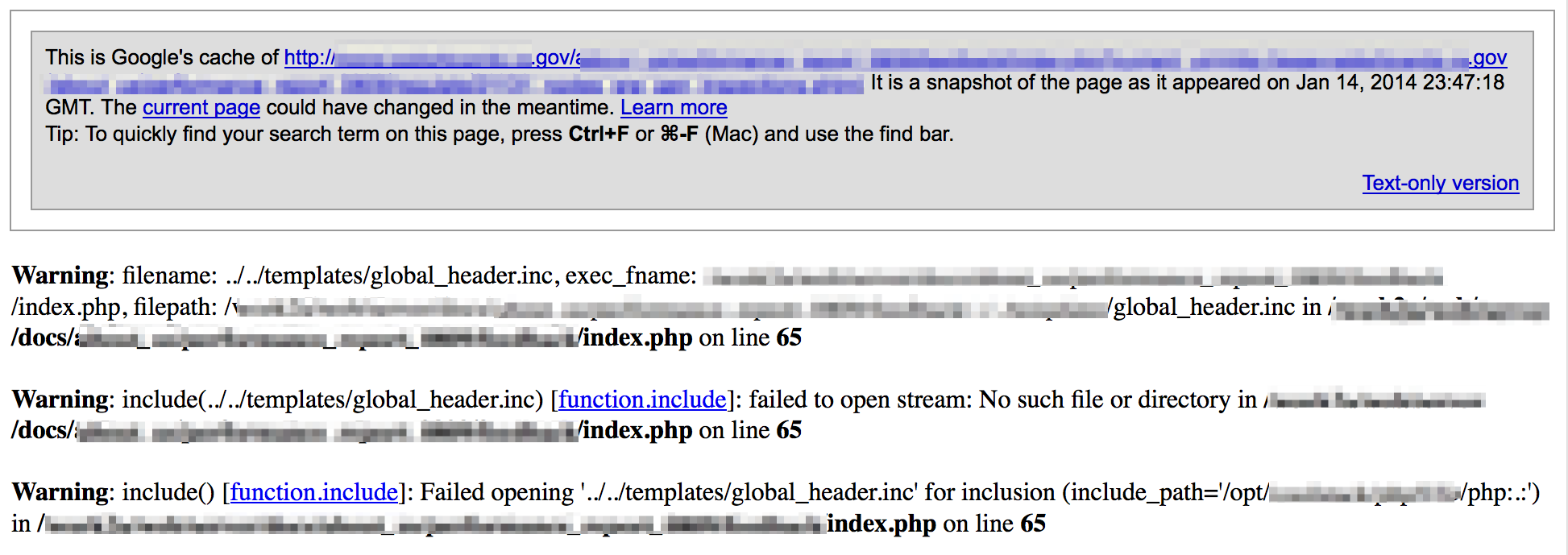
SQL injection lends itself quite nicely to being detected by robust error messages. This is another example of where knowing what technology the site is using will help scope your searches. For example, if it’s a PHP/MySQL shop you’ve got obvious error signatures such as intext:mysql, intext:”error in your sql syntax”, intext:”check the manual” filetype:php , etc…

The same can be done for SQL Server, Oracle, etc:

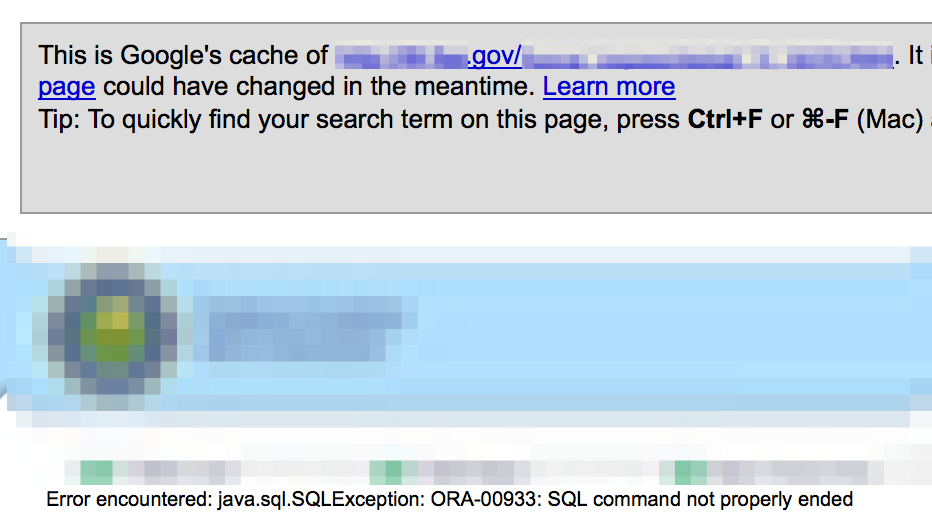
As you’re browsing the site, also be on the lookout for SSL errors, particularly on commonly used organizational web or email portals — especially if you plan on incorporating man-in-the-middle attacks into your pentest.
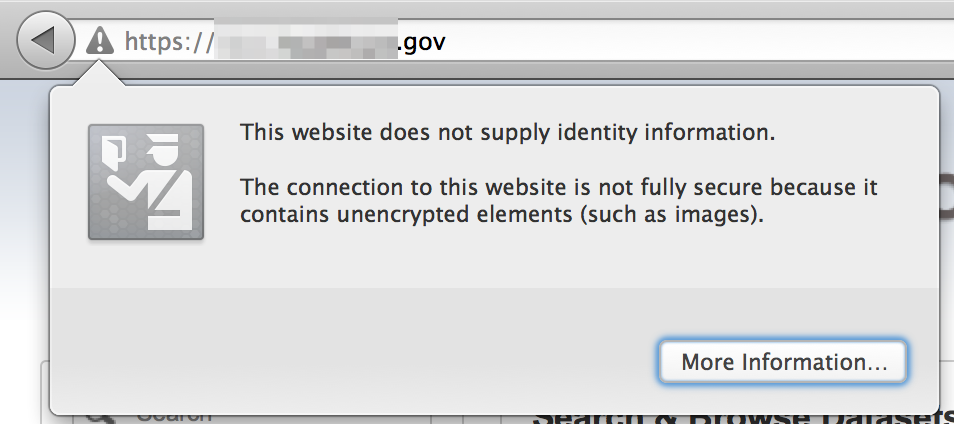
There are so many additional vulnerabilities that can be discovered via passive reconnaissance, but I won’t bother to go any further here because I think you get the gist. Again, check out the Google Hacking Database for more ideas.
Conclusion
Hopefully this tutorial has demonstrated some of the ways in which passive reconnaissance can be useful as part of your security testing activities. It’s obviously not a replacement for active testing and only scratches the surface when it comes to discovering vulnerabilities but it can certainly provide some valuable information to help scope your testing efforts.
The examples provided in this post also serve to illustrate the security problems that continue to plague websites, big and small. To be fair, the .gov domain is large, with thousands of websites encompassing everything from the federal to the local city and county governments, with each organization responsible for their own security. It’s to be expected that some are better at security than others but I saw potentially significant problems across the board. For the most part, I restricted my public domain searching to Federal and State sites as they provided more than enough examples…though there were plenty more at lower levels as well. Keep in mind much of what is demonstrated may not constitute exploitable vulnerabilities, though I did identify (and report) several that most certainly were.
If you haven’t already, consider incorporating passive reconnaissance techniques into your penetration testing or security assessment approach. More importantly, if you are responsible for securing your organization’s public Internet presence, be sure to perform passive reconnaissance against your own sites!
If you found this post useful or if you think I omitted any key techniques or uses for passive recon, don’t hesitate to let me know in the comments section or on Twitter!